# Motive Matters
URL: https://www.abhinav.co/motive-matters
Date: 2011-04-15T00:00:00+00:00
Dr Michael Sandel, Professor of Philosophy at Harvard, teaches a very
popular and widely attended course - "Justice - what is right thing to do".
These lectures are also available online. Although many a times,
ideas discussed are very abstract in nature, but Prof Sandel keeps
them interesting by
involving his students in the discussion.
Through one such lectures, I got to know about Philosopher and
Teacher, Immanuel Kant. Kant, while answering what is morally right,
gives an example of a shopkeeper,
who avoids cheating his customers because he thinks word may get out
and it may negatively hurt his business. As per Kant, although the
shopkeeper does the right thing, but his action is morally wrong. A morally right thing to do
not only means doing what's right,
but also doing it for the right reasons. Motive matters.
Kant mentions duty and inclinations, and argues that morally right is
done for sake of duty and not for selfish inclinations. Consider this - if a shopkeeper
does not cheat his customers because he thinks he is a moral person,
then again, he is morally wrong. He should consider it as his duty.
In Hindu context, this is exactly what Krishna said in Geeta, and we almost
always misunderstand the message.
Doing your duty without considering the potential benefit you might
get is the right thing to do (_Karmanye ma phaleshu kadachana_)
whereas the common notion is doing your duty will improve your karma
points which will help you later (if you believe in reincarnation,
they might be helpful in laters births too). Hope you see that all of this is morally wrong.
---
# What is your good name?
URL: https://www.abhinav.co/what-is-your-good-name
Date: 2011-06-23T00:00:00+00:00
Have you ever wondered how kids learn their first set of languages,
and how it is different from the way, we grown-ups, learn new languages?
I think, kids learn them and the real world at the same time,
hence they map words with real things - like the word 'chocolate' with
something sweet in a wrapper they love to eat.
On the other hand, when grown-ups try to learn one - they
mostly map words in it with corresponding words in the language they
already know - like 'halu' in Kannada means milk.
Intuitively, the grown-ups' way of learning new languages looks more
efficient, but if you have ever tried learning a new language, you
will know it's not that easy. Somehow,
kids seem to pick languages easily than grown-ups. Of course, there are
people who are very good at picking them up, and can learn multiple
languages with comparatively ease,
but they are more or less exceptions. Another problem with grown-ups'
way is that they are limited by knowledge of
their previous known languages.
I think all this holds true for programming languages too. When you
learn your first programming language - you are not only learning a
new language, you are learning programming too.
After that, every new programming language you learn you subconsciously
try to map it's constructs with known ones. And this is when, for
starters, learning one from a different paradigm
seems very tough. In my particular case, I found it extremely hard to
learn second programming language (after C) because I was trying to learn
C++ and Java, which are from a
different paradigm of object oriented programming. I gave up and
instead learnt Perl, gradually started using objects in it and finally
learnt object oriented programming.
Although I am still a beginner in funtional programming, but I think
object oriented programming to functional programming jump was
comparatively easy.
Be it human languages or programming ones, you learn them by practicing
them. And in this context, I feel, programming languages are easier to
learn than human languages. It takes courage
and readiness to make mistakes to learn new human languages, and
therefore, not surprsingly, you will still find me trying to use Hindi instead
of Kannada on the streets of Bangalore.
PS: "What is your good name" is literal Hindi transalation of "Aapka
shubh naam kya hai", a polite way of asking somebody's name in North
India.
---
# Future of Mobile Apps
URL: https://www.abhinav.co/future-of-mobile-apps
Date: 2015-04-26T00:00:00+00:00
I found it hard to convey my thoughts in form of coherent text, wrote in points instead.
{: .notice}
* Today's desktop browsers are very powerful. We use them for communication,
entertainment and almost all our needs. And we use search engines
and social networks to discover websites and pages.
* Mobile OS market is pretty fragmented with iOS, android and windows platforms.
It is difficult for app makers to develop, maintain and market native apps for all these
platforms.
* It is also very difficult for consumers to discover and download all these
special purpose apps. There are no equivalent alternatives for search engines
in mobile world.
* Mobile phones are yet to develop an app like desktop browsers - an app which
can become your interface to other apps.
* Cards presents a brilliant interface for other micro-apps to run inside one
app. Look at Google Now to experience these cards.
* I believe, these micro-apps are the future and an app, with the ability to run
these micro-apps inside itself, will rule the mobile world.
* Probably, Facebook and Google are already working towards this. Facebook Messenger has
opened up it's platform for businesses, whereas I think, Google is approaching
this as a technology problem and is trying to make chrome on android more
powerful and better. They also have Google Now which they can open up for other
third party integrations.
* The way these micro-apps will interact with users will be very different from
traditional pull based search engine model. Interaction will be more contextual and
personalized depending upon users' habits and preferences. It will also be
more pushed based then pull. It is the future of Siri too.
---
# The Country of the Blind
URL: https://www.abhinav.co/the-country-of-the-blind
Date: 2015-05-05T00:00:00+00:00
As a kid I have read a few stories that have stayed in my mind and thoughts for years now. This post is about one of such stories that I read in my English text-book - "The Country of the Blind". I don't remember the exact class I read it in, but even during those days, it made me think about evolution and as a society, how hard it is to accept something which is different from our own established notion of correctness. This is how I remember the story:
In a valley near Ecuador, a small tribe of people is cut-off from rest of the world by an earthquake which has blocked the only passage from outside world to the valley. This isolated tribe, though prosperous and self-sufficient, suffers an epidemic and everybody looses their vision. Children also start to take birth blind. Over time society adapts itself to life without sight; concept of sight and vision is lost.
After a few centuries, one of the mountaineers from outside world gets lost and slips into this part of the world. Mountaineer, among other things, notices that people of this tribe prefer sleeping during the day when it is hot and work in night when it is cool. Their idea of beauty is also not conventional for they consider people with rough skin as more beautiful. This surprises him, and remembering the proverb 'in the country of blind, the one-eye man is king', he starts seeing the opportunity to rule the tribe. He tries explaining the concept of sight to everyone but fails. In fact, whole tribe starts thinking of his obsession with sight as a disease. To make him 'normal', tribe doctors propose an operation to remove his faulty eyes. Having fallen in love with a girl, and wanting to marry her, he reluctantly agrees. However at the sunrise before the operation, when whole tribe is asleep, he leaves to escape the valley.
This story is brilliant. When I first read it, it took me some time to accept the fact that people with no concept of sight and vision will find person with ability to see as abnormal. It opened my mind to the thought that, at times, an idea or perspective, however counter-intuitive it may seem to you and to whole of your little society, can actually be right and valid for other societies. Similarly, many old traditions may seem irrelevant now, but probably in the past they all made sense.
I believe we all need to be a bit more considerate about others' ideas and traditions. We need to try not to look at the world as black and white, but with some shades of grey. Does God exist or is there any answer for which religion is the best? Or is capitalism better than socialism? Or is it morally obligatory to be a vegetarian? Is my country better than yours? Or is static typing better than dynamic typing or vi better than emacs? Though one certainly has the right to have one's own opinions, but does fighting over them make sense? Fundamentalism of any kind is bad.
>It's not only moving that creates new starting points. Sometimes all it takes is a subtle shift in perspective, an opening of the mind, an intentional pause and reset, or a new route to start to see new options and new possibilities.
- Kristin Armstrong
At times, we fail to empathize with each other, because we fail to understand each other's viewpoint. As we move forward, one of the most important requirements to be a world citizen would be to develop empathy and an open mind. Develop and grow.
---
# Growing startups and technical debt
URL: https://www.abhinav.co/growing-startups-and-tech-debt
Date: 2015-06-06T00:00:00+00:00
I recently read a post - [Why the way we look at technical debt is wrong.](https://bigeng.io/post/118399425343/why-the-way-we-look-at-technical-debt-is-wrong)
I do agree that for a company it is important to reach to its users as soon as possible. However, in my opinion, a growing startup, which has got millions of active users, but is still struggling to find product-market fit, can not afford to take a lot of short-term calls very frequently.
Although a company can be structured such that small teams function as independent startups, but if team hasn't invested in building frameworks, modules and services and writing good code in general, their iteration speed will be slow. And most unfortunate thing for a company with slow iteration speed would be it's inability to cope with growing number of users and their requests. I think, each growing startup needs to understand the scale at which it operates and how to try out various things in a controlled manner.
Agility is important. And, however well one plans, after every x time, one will have to fix technical debt - because market behaves differently from assumptions made, and to calibrate with that, one will change code/feature to incur some technical debt.
The way to look at this is to build version 0 which can help to validate initial assumptions and then version 1 and so on - this should happen more from product perspective than code. Assuming that code which was written for version 0 will work with version 2 is not right and this is the most common problem which most non-technical product owners face. They should accept that it may so happen that one will have to go and rewrite whole code for version 2.
Companies need to choose - whether going to market early is important or later iterations are also as important. Twitter was built in two days (it was a matter of do or die for them), and you will also remember "fail whales" - it took them more than a year to fix just that. Similarly, Amit Singhal did a complete rewrite of Google’s search engine in 2001.
Another thing which works very well for smaller startups, but affects mid-sized growing startup in a negative manner is chaos in the company. Reducing chaos, so that every employee can focus is important. You loose a lot in context switch - at times, this is unavoidable, but accepting it as normal is a problem.
Such companies also need an environment where everybody is productive and people only worry about problems in hand. Employees use abstractions, work at higher level and also build abstractions for others. Startups mean chaos - true, but according to me, it should be imposed by market forces only. And even then, attempt should be made to reduce it.
It is said successful entrepreneurs take only calculated risks and work towards minimising them. I believe, they also work to allow only structured chaos in their companies. Look around, all successful entrepreneurs and companies have done the same.
---
# Ten years
URL: https://www.abhinav.co/10-years
Date: 2015-07-04T00:00:00+00:00
Ten years ago, on this day, I started working at my first job. I was in Bangalore for six months already and had interned at LG before. I still remember the day I joined, and what I wore that day - a blue shirt, which as a ritual, I wore on first days for next couple of jobs as well. Because of a certain confusion, HR department and my manager didn't know that I was joining that day and hence no computer and seat was arranged for me. I spent whole day exploring FreeBSD for the very first time on a temporary desktop.
Overtime, I got to know my colleagues and Yahoo! better. Yahoo! felt very different as a company. There were a lot of talented and creative engineers around, and it was overwhelming. And I believe, being overwhelmed was the right state to be in. Over a course of two years, I learnt a lot of new things, some very obvious and some very different.
I spent some time reading a lot of good quality code written by one of my team members, Ajay. And within six months, I was copying his style. I learnt how to write production grade code, how to handle 1B+ user records and a fair amount of internal technologies. If you are a Yahoo, you would remember `udb` - a multi-region, NoSQL DB, even before the term NoSQL was invented, `repl` - data stream APIs, `yinst` - best package manager I know of, `ypan` - Yahoo's Perl library collection, `yroot` - docker like containers, `yjoin` - my most favorite technology using which I wrote a flat file based database, `yfreebsd`, `yapache`, `yphp` and many others. Hadoop was just starting to come out. In terms of software infrastructure, Yahoo! was ahead by miles when compared to the rest of the world.
After a few months of joining, my manager, Mahesh started asking me to reply to the emails sent by US team on a regular basis. For initial few months, I felt uncomfortable doing this, but eventually I learnt and started enjoying it. Only after that I understood what Mahesh had done for me. He not only made me comfortable in formal dialogue via emails, he also made everyone in the US team know about me. I was not an anonymous software engineer in another continent anymore. Now, when I mentor people, I try to do something similar whenever possible.
I gained a lot of confidence at Yahoo! and that confidence prompted me to take the next step, trying my hand at starting a new company. However, I realized, I had a lot of learn, and therefore I joined Ahmedabad based NirmaLabs for six months grooming programme. It was an eye-opener and I learnt about design, product, marketing, sales and finance. I also met one of the smartest people I have ever met - Dr. Madhu Mehta. Although I rarely get to talk to him these days, but I still consider him as one of my mentors. I admire him ardently for his clarity in thought and speech, and his determination to support and mentor budding entrepreneurs. By late 2007, Google had released Android framework, Apple had released iPhone. It was challenging but exciting time. However, in retrospect, I don't think I worked hard enough executing my startup idea, and gave up too quickly because of external and personal reasons.
Economy was moving into recession, and I freelanced for a while, before joining ShipX. ShipX holds a special place in my professional journey, for not only I picked up whole set of new technologies, I also learnt about logistics, supply-chain domains and how business is done in India. We did a lot of iterations, added numerous new features, and got paying customers. I understood how real world processes and flows are modeled into software flows. Though times were tough and I worked some months without salary, but I gained a lot of skills and knowledge from Venky, Yegnesh, Maxin, Laxman and especially Amar, who treated me like his family member.
I eventually left ShipX after working there for close to two and a half years - longest I have worked in any company. It was a very hard decision. I joined a games startup called PlayUp - they were just starting their social gaming vertical, I joined the engineering team and worked on a couple of interesting games. I started as an individual contributor, but in between started leading a team of talented engineers. We not only delivered products on time, we wrote good quality code with right set of engineering practices. It is here, where I developed a lot of platform microservices (I didn't know the term then) and assembled them to create scalable backend. We also started to work on single page apps using frameworks like backbone.js - learnt a lot, discovered hidden leader inside me. I must thank CTO, Kangesh, for convincing me to lead the team.
I was itching to do a startup again, and left PlayUp just after a year. Idea we started working on was brilliant and ahead of its time. We built a fantastic product in a short span of six months, but alas, we could not continue because of unavoidable circumstances.
I was about to get married, and yet again, I was without a job. Shikhi had just told about the wedding in her office, and her company, in response of her brilliant work, as an exception, had given her an opportunity to work from Gurgaon office. Now I needed a job badly in Gurgaon and after a few tensed weeks, I found one - at hike messenger. Most I liked about hike was its engineering driven culture, which was and still is an exception in Gurgaon. I restarted again as an individual contributor, and in past two years, have worked at a critical juncture of hike’s growth.
I have worked in small companies and I have worked for large companies, but for the very first time in my life, I am working for a company which is transforming itself from a small one to large. It's tough, chaotic, but very satisfying. Hike is poised to win in this market, and I would like to believe, in however small way, I am contributing to its success.
Rare and lucky are those, who know very early on, exactly where they will end up. I don't know what future holds for me. I am reminded of an incident, when in year 2000, I went to a cyber-cafe for the very first time with a friend. He wanted to check his email, and I saw Yahoo! webpage. He entered his username and while entering his password, he asked me to look away. Though I understood immediately that he is entering something which is private and required to see his email, but when I sneaked through, I could not understand why he would keep six asterisks (*) as password - I didn't know then that webpages don't show passwords on screen. Nor I knew that I would work for this funnily named company in the near future. Similarly, in my whole school life, I didn't know that there existed a place called Pilani and I would end up studying there.
If you ask me whether I have achieved all I wanted to achieve in ten years, answer is no. I have failed miserably and not just once, but multiple times. At the same time, most of the things that I have learnt, I could have not learnt without failing. My bucketlist is full of tens of items, and I understand that however hard I may try, I can never anticipate what I would end up doing in future. However, I pray that I keep learning and keep trying. And, that I start feeling overwhelmed again.
---
# Speed
URL: https://www.abhinav.co/speed
Date: 2015-08-15T00:00:00+00:00
I recently read a post - [Speed as a habit.](https://firstround.com/review/speed-as-a-habit/)
It's a great post, and I agree with the author on almost everything. It is very common to see decision-makers knowingly or unknowingly affect the speed of the project because they can't choose one thing over other. They work in an iterative fashion, delay making timely decisions and therefore, they miss global optimum and have to settle for local optimum. Difference between global and local optimum is called as technical debt and it requires them to stop frequently and pay this debt.
This is how I look at speed. Imagine a vehicle moving in speed, and then suddenly if you ask the driver to take a turn - vehicle has to either slow down considerably, or it will crash. Only possible way to complete the whole route from start to end is that you take timely decisions and stick to them. This does not mean that you don't take any turns at all, but instead you plan for them and also minimize them. Taking too many turns will only affect your speed.
The most important pre-requirement for speed is setting a goal and deciding a path. My advice is to take time in deciding, and plan for at least next couple of milestones, but once you have, stick to it. Revaluate when you have achieved those milestones. However, overall bigger vision is also important for you to get closer to global optimum than local optimum and avoid very short term calls.
> It is a mistake to think that moving fast is the same as actually going somewhere.
> ― Steve Goodier
---
# Game Theory and Public Systems
URL: https://www.abhinav.co/game-theory-and-public-systems
Date: 2015-09-26T00:00:00+00:00
From a game theoretic point of view, in a game, each player acts according to his incentives. He chooses a strategy that maximizes his payoff, taking into account of other players possible strategies. And in a well designed system, protocols and incentives are designed such that payoffs are maximum for a player when he follow the rules of the game (or at least most of the rules most of the time.) In other words, honesty is just a strategy and most players choose to follow it in such games.
If you look at public systems as a game, each stakeholder's behaviour is nothing but a strategy to maximize the payoffs (money, power, authority or otherwise.) And the way our systems are designed, we penalize wrong behaviour, and almost never incentivize the honest behaviour. Most of the times, it is possible for a stakeholder to maximize his payoffs by dishonest means and to never get caught, and this is the root cause for the increasing corruption in public systems today. Anti-corruption departments (incuding proposed lokpal) focus on reducing corruption by only finding corrupt officers and penalizing them. (Delhi state government has taken it to extreme by asking citizens, who are also stakeholders in the system, to conduct sting operations to expose corruption.)
I think, we need to design our public systems in such a way that they incentivize honest behaviour. If a stakeholder gains more by being honest, as a rational being, he will choose to be honest. I understand designing such systems are hard, but in my opinion they have a better chance in fixing corruption which today seems to be a systemic characteristic of our economy and society.
As I study more about better designed systems in India and elsewhere, I will try to write basic ideas behind them in future blog posts.
---
# Digital Colonies
URL: https://www.abhinav.co/digital-colonies
Date: 2016-10-22T00:00:00+00:00
I always wondered if our government was wrong to throw out multinational companies like IBM and Coca Cola from the country in 1970s. If they had not, the liberalization process and growth which started only after 1992, could have started much earlier. Similarly, I also used to believe that Chinese government is wrong in providing unfair advantages to Chinese companies over global Internet giants. Perhaps I did not have an open mind to understand other perspectives.
To be clear, I am against government's control of information and thereby minds, however much like how colonial powers fought to control over weaker countries and the new world, I also see that our attention and time as the new resources which these new age digital companies fight to acquire. And they have been successful so far.
Today's world is driven by growth; investors and shareholders want their investments to keep growing and therefore, it is important, even for existing successful companies, to keep investing in building new platforms to sustain growth. Did you ever wonder why Facebook bought Oculus, why Google built Android and Chrome, or why both Apple and Google are interested in cars as a platform?
As a person with entrepreneurial bent, I worry about this - ten years ago, when I first tried starting up, world was very different, and it was still possible for a young startup to compete and grow. However, today it scares me to see some of the well-funded Indian companies struggle against global counterparts. I think it is exponentially difficult to build a successful company from scratch now.
Believe it or not, we are digital colonies of these new age technology companies.
---
# Inflation
URL: https://www.abhinav.co/inflation
Date: 2016-10-27T00:00:00+00:00
We take inflation for granted. We relate it with growing economies, and we see zero inflation and deflation as a sign of stagnating or shrinking economies.
Inflation in elementary terms is sustained increase in price level of goods over a period of time. For example, last year, if one could buy 1 kg of apples in 100 rupees, and now if they cost 110 rupees, simplistically speaking, inflation in apple prices is around 10%.
Prices are usually decided by demand and supply equilibrium, and it is quite natural to believe that price inflation happens because of increase in demand which also indicates growth.
However, inflation can also increase if currency starts loosing its value. And when does that happen - when government start printing more currency than it really should. It helps in the short term, however in today's globalized world, it has a big negative impact in the longer term.
This is what distinguish money from currency. Money has the ability to preserve its value over the longer term, that is, unlike money, a currency is subject to inflation.
On a related note, this is the reason Satoshi Nakamoto designed Bitcoin to have a cap. I will write more on Bitcoin in later posts.
---
# Start up vs Big Company
URL: https://www.abhinav.co/startup-and-its-people
Date: 2016-11-08T00:00:00+00:00
Your company is no longer a startup if it can succeed without its people succeeding or its people can succeed without it succeeding. First thing happens when your company has people who are no longer needed, second thing happens when you have unnecessary bureaucracy in your company.
---
# GCP vs AWS
URL: https://www.abhinav.co/GCP-vs-AWS
Date: 2016-12-10T00:00:00+00:00
[Ben Thompson](https://twitter.com/benthompson?ref_src=https%3A%2F%2Fabhinavsaxena.com) of Stratechery recently wrote a post on [how Google Cloud Platform is challenging AWS](https://stratechery.com/2016/how-google-cloud-platform-is-challenging-aws/?ref_src=http%3A%2F%2Fabhinavsaxena.com). It's a very well thought out and interesting post.
I think, AWS is Amazon's Android and GCP is Google's iPhone. To continue with the analogy, AWS has its own 'GMS' - Google Mobility Services in form of services like RDS, lambda, S3 and has a 'Playstore' with services like redis-labs, loggly etc. (In fact, Heroku, a PAAS service which runs over AWS has much richer [add-on ecosystem](https://elements.heroku.com/addons?ref_src=http%3A%2F%2Fabhinavsaxena.com))
For many startups and developers, AWS has become key part of their tech stack (directly, or indirectly via heroku, engineyard etc.) Weirder, however not very inappropriate, analogy would be that for these startups AWS is like TCP/IP, underlying layer over which HTTP and browsers work. And through AWS, Amazon controls a lot of world's tech infrastructure. In Chamath Palihapitiya's words, [AWS is a tax on the compute economy](https://www.quora.com/If-Chamath-Palihapitiya-had-to-put-all-of-his-money-in-one-investment-today-with-a-10-year-holding-period-what-would-it-be?ref_src=http%3A%2F%2Fabhinavsaxena.com). Google has just woken up to this - and therefore I think it's a very strategic move, and not just a new business model or revenue stream for Google. Why should an app on Android Playstore be backed by AWS?
Google app-engine which is/was far superior in terms of its technology offering never picked up because there was a lock-in and it's ironical yet brilliant that they are pushing Kubernetes so heavily now - very interesting times ahead.
---
# From a great consumer product to a lasting tech giant
URL: https://www.abhinav.co/lasting-tech-giant
Date: 2017-01-08T00:00:00+00:00
I love twitter for their product, and have spent some time thinking why it’s not succeeding as a company. As far as my naive thinking goes, there are more than 140 million users like me who use Twitter everyday and love it - it’s a great consumer product. But when it comes to growth as a business, it’s on a downhill.
From this context I have been thinking about how do companies become lasting giants, and have realised that it essentially boils down to two *not-so-easy* steps:
*Step 0* - create a product which your (niche) target customers love, grow it, and achieve product market fit. Easier said than done, however a lot of companies stop here (either they get acquired or perish - ex. WhatsApp, Yahoo, Pinterest, Dropbox)
*Step 1* - bring at least one other type of users (network) on your platform who create value for your consumers. They could be developers, sellers, property owners etc. If interaction between both of these networks is more efficient than any other existing mechanisms, it creates a huge network effect, and help the company elevate its status from a great company to a lasting giant.
It is arguable that advertisers (as the other type of users) alone can help create lasting companies. IMO, they don’t add enough value for the consumers, and therefore more often than not, companies need to add another types of users. I believe this is the reason Google & Apple need developers and apps on their platforms.
Amazon is a marketplace for a while now. Similarly, though it was hard for marketplaces like Uber & AirBnB to solve chicken and egg problem (step 0), but once they have, now they are unstoppable. On the other hand, Yahoo, for example, eventually perished because it only had advertisers. Facebook may look like as an exception, however in its pre-mobile days, its growth was largely fuelled by its developer platform, and these days content providers create that value for consumers which keeps advertisers interested.
It will not be easy for Twitter, however it needs to start moving from step 0 to step 1 as soon as possible. It has played an integral role in numerous social movements like Arab Spring, and world needs Twitter to exist.
---
# Speed and Quality
URL: https://www.abhinav.co/speed-vs-quality
Date: 2018-10-06T00:00:00+00:00
Speed vs Quality is a common debate in engineering and product organizations and though it is hard to move at speed while maintaining quality, but I believe it is not completely impossible. Here are some tips (in no specific order) to balance between the two
* Understand the product vision, and then engineer MVP or first version. Aim should be to develop an extensible but not the eventual system on day one. Focus on getting an end-to-end happy flow working, then edge cases, and then new scope changes.
* Do enough but do it well.
* ABC - always be closing. Minimize number of things in flight, if given multiple tasks simultaneously, always ask for priority.
Be open about writing use and throw code.
* Know what to do on server and what do on client. Initiate cross-team collaboration from planning stage.
* Don’t over-engineer (premature optimization is root cause of all evils.)
* Know when to hack and when not to hack. Know difference between good hacks and bad hacks. Keep them modular and separated from other code to allow easy refactoring/removing.
* Understand difference between tech-debt and bad code. Tech debt is something which is stopping you from moving at optimal speed; if not, it's just non-ideal/bad code. Don't try to fix it.
* Remember, tech-debt occurs when you take shortcuts and tightly couple your code. To take shortcuts, make sure to modularize your changes as much as you can.
* Leave the campground cleaner than you found it. No big refactoring projects, but continuous refactoring. If a feature takes 5 days to build, and refactoring a piece surrounding that takes 1 day - take 6 days and refactor.
* First make system correct and then make it efficient and not vice-versa (Correctness over Efficiency.)
* Though perceived otherwise, but practices like unit testing, code reviews, architecture reviews and automation helps in gaining speed while maintaining quality. Unit-test your code, and invest in automation. Find high-quality reviewers, and take feedback from at least a couple of them.
* Use a task tracking tool, and be religious about it.
* Be pro-active, and push information to other stakeholders early and more frequently. Being on same page helps a lot both with speed and quality. On a similar note, ensure silos are not formed - they give you speed in shorter term, but slow you down in longer term.
* Do frequent releases - if there are frequent releases, it automatically helps in avoiding scope creeps. Product owners know that they will get a chance to add changes in next release if changes don’t go in this release. This also means, that release dates need to be sacrosanct and if there’s a delay, everybody involved is informed as soon as possible.
> It is a mistake to think that moving fast is the same as actually going somewhere.
> ― Steve Goodier
---
# How to engineer an MVP
URL: https://www.abhinav.co/how-to-engineer-an-mvp
Date: 2018-10-08T00:00:00+00:00
As per wikipedia, MVP or Minimal Viable Product is a product with just enough features to satisfy early customers, and to provide feedback for future product development.
While it's a known paradigm in lean startup philosophy, however I have seen a lot of product engineering teams struggle to create one which can yield valuable learnings quickly. Here are some of my recommendations to product and engineering teams to help them create a good MVP.
### Before you start
* Though it is important that PMs think unconstrained while trying to build the product, however EM (and/or senior engineers) in the team should be consulted before MVP spec is locked down
* PMs should clearly communicate to engineering team the vision of the product and should list down set of hypotheses they are trying to validate from this MVP - this helps engineering team understand set of non-negotiable components and visualize future requirements
* Engineering team should also ask PMs to list down a couple of directions this MVP can take - through this engineering team can understand components which need flexibility and will change soon after.
* Remember MVP is principally a learning product, and iteration speeds will play an important to adapt product for users’ needs. Engineering team should find out time duration PMs will take to validate initial set of hypotheses - this will play a key role in deciding how much hacky/non-optimal code will be okay. If PMs can validate hypotheses in a couple of days, before team is required to work on V1 - team should likely not hack much or build code which can be iterated for V1 quickly. However if validation time is large, engineering team can enable PMs with quickly built MVP, and find time to build V1 while PMs validate the solution with users.
### Building
* Engineering is all about balancing the trade-offs and so is engineering an MVP. Good engineering teams know that right problems need to be solved at right stage, and solving them prematurely or too late can be fatal. Example - building generic systems or scaling them prematurely can waste a lot of important time, while continuing with non-optimal systems or processes for long can negatively impact your iteration speed.
* Though it is outside of scope for this document to define what is a good hack and what is a bad one, try to avoid bad hacks as much as you can. Example - hardcoding keys in client is a bad hack.
* Contain your hack. Spend time in finalizing contracts, input and output parameters - this gives you flexibility to implement API/module non-ideally and fix/refactor it later on without a need for large scale refactoring.
* Document your assumptions clearly - most of the hacks are actually nothing but assumptions which may not stay valid later on - document them, and share them widely in the team so that these hacks can be fixed at right time.
* Don’t automate from day one, but if you are spending 1+ hour as a team everyday in doing something manually, automate (at least partially) if you can.
* Backend and frontend should settle on API contracts as soon as they can, so that frontend team can stub API calls and develop in parallel. However, integration between backend and frontend should happen as early as possible - this avoids fixing mismatch of assumptions at the last moment.
---
# Slack Etiquette
URL: https://www.abhinav.co/slack-etiquettes
Date: 2020-06-20T00:00:00+00:00
Slack has become an important tool to make the workplace more collaborative. However, it has also become the primary reason for stress, fatigue and degraded productivity. Here are some basic etiquette to keep in mind:
## Email
- Slack is not email - if you are using Slack as a replacement for email, then there's something wrong. (example: weekly status reports, product specs, engineering design etc. ideally should be over wiki/email)
- Slack isn't meant for deep discussions that last for days/weeks. Use email instead.
- Slack is meant for ephemeral communication. Avoid taking decisions on Slack, and if you do - send an email or note them down in appropriate documents. Slack messages get lost very easily.
## Channels
- Default to public channels. Create a private channel if you want it to be accessible only to a few folks
- If you are creating a channel, follow your org's convention of naming channels (including underscore vs hyphen in the channel name)
- If you are part of a private channel, don't add more folks without asking the person who created or is running the channel.
- Archive channels that are no longer needed.
- Every channel must have a specific reason for existence. This might be different from the stated purpose on Slack. If a lot of channels have similar set of members, and they talk about the similar things in all the channels - merge them (by archiving other channels)
## Direct Messages (DM)
- DMs create silos and information asymmetry. I am a big fan of [Stripe's email transparency](https://stripe.com/blog/email-transparency) culture, and hence I insist on minimising DMs as much as possible.
- If more than 2 people have messaged you asking the same thing, you should consider putting your answer in a channel or a document.
- Slack allows you to DM upto 7 people at once, however I recommend at max 3 people DMs (including you), if you want to talk to more at once - use an existing channel, create a new channel (avoid it as much as possible though) or take this conversation over email. Adding more folks and giving them context about the discussion is much easier that way.
- In the WFH world like today, I would recommend not sending a DM after work hours. DMs create notifications. Send an email instead. This way the receiver can process the message at his own time.
- If you choose to DM, put the whole question in first message itself - it's stupid to message hi/hey and wait for other person to respond. By writing down the whole message, you also let the receiver decide the priority of the message.
## @Channel
- Use @channel if you really want everyone to take a note right away. Usually these situations are only emergency situations.
- Think twice before using @channel in a channel of more than 10 people during off hours. Consider using @here.
- Most of the @channel messages sent during off hours can be sent in normal working hours. Consider doing that. This helps ensure that importance of @channel message is retained, and they get enough attention from everyone
- If your channel is a support channel (ex. IT-support), consider creating a user-group (ex. @it-support) as well - this will ensure anyone needing urgent help doesn't have to @channel and disturb everyone who is in the channel to seek help.
## Conversations
- Don't be a grammar nazi
- Use DPs and add your title - there are enough bots already on Slack, you don't need to be one.
- Acknowledge messages. You can use emojis or reactions, but do acknowledge the message.
- Many times, if you are writing a really long message, it's a signal that this message probably should be sent over email. In case, you still want to go ahead, make it easy to scan by adding line breaks, bullets, and text styling.
- Utilise threads, especially for happy birthday/congratulations messages. Avoid using a separate message as much as you can.
## Availability
- One of least used features of Slack is Status - use it effectively to communicate if you are away from work.
- Pause notifications/use DND in case you are in a meeting, or working on something important. Notifications should not distract you from the work at hand.
---
# Blockr
URL: https://www.abhinav.co/blockr
Date: 2020-07-28T00:00:00+00:00
There are distractions all around. Our attention span is continuously decreasing, and so is our ability to focus and do deep work.
blockr is a command line tool to easily **block** websites to avoid distractions. At the same time, blockr makes it extremely easy to **unblock** websites in case you need to access them.
If you prefer a different workflow and like focussed and relaxed modes, blockr also lets you switch between these modes ensuring you are able to access blocked websites in relaxed mode - blockr provides **activate** and **deactivate** command to support this use case.
Please note this is alpha software, and is currently tested only on mac (Apple's OSX)
### Installation
```
$ sudo gem install blockr
```
### Commands
```
$ blockr block [WEBSITES] # block websites; shortcut -d
$ blockr unblock [WEBSITES] # unblock websites; shortcut -u
$ blockr activate # activate blockr, make all websites blocked by blockr inaccessible; shortcut -a
$ blockr deactivate # deactivate focus mode, make all blocked websites accessible; shortcut -d
$ blockr help [COMMAND] # Describe available commands or one specific command
```
### Examples
```
$ sudo blockr -b www.example.com # block
$ sudo blockr -u www.example.com # unblock
$ sudo blockr -a # activate focus mode
$ sudo blockr -d # deactivate focus mode
```
### Source code
Source code is present on [Github](https://github.com/abhinavs/blockr) - please check [README](https://github.com/abhinavs/blockr/blob/master/README.md) for more detailed documentation.
### Website
Please check [project home](https://www.abhinav.co/blockr.html) for regular updates.
---
# Microrequests
URL: https://www.abhinav.co/microrequests
Date: 2020-08-18T00:00:00+00:00
Microservices have slowly become the chosen way of building systems in large and small companies - they work because they allow decentralisation and the separation of concern which helps when the number of teams in an organisation starts growing.
Microservices, however, also present some challenges. One of them is to keep communication between different microservices simple and easy yet performant.
There are a lot of ways in which microservices can talk to each other, one of the most popular ways is to use HTTP APIs (including REST APIs) - HTTP is a sort of stateless protocol, and by default is a bit inefficient to use from the latency point of view if you have to call many microservices to serve one client-facing request.
Microrequests makes consuming microservices in Python more efficient. Python’s requests module is fantastic and highly configurable, microrequests builds a wrapper over requests module and enables connection pooling as part of initialisation. This ensures that you use the same connection instead of creating one with every new request, while still working with requests’ clean APIs and mechanisms.
### Installation
The easiest way to install microrequests is using pip
```sh
$ pip install microrequests
```
### Usage
To use, simply do::
```python
import microrequests
mr = microrequests.init()
# mr is requests' session object and you can use it in similar manner
res = mr.get("http://httpbin.org/get")
print(res.text)
```
You can also customize max_retries, pool_connections, and pool_maxsize - they are by default set to 1, 100 and 50 respectively; pool_connections is the number of urllib3 connection pools to cache and poolmaxsize is the maximum number of connections to save in the pool
```python
import microrequests
mr = microrequests.init(max_retries=2, pool_connections=10, pool_size=5)
res = mr.get("http://httpbin.org/get")
print(res.text)
```
### Future Work
In the future, I intend to add more nifty ways to make consuming microservices easy and efficient. I also want to experiment websockets as a communication protocol instead of RPC or HTTP - a lot of backend frameworks in various programming languages now support websockets and interface is mostly clean, however consuming microservices using websockets is still not mainstream and interfaces are still ugly. I intend to work on this.
### Source Code
Source code is present on [Github](https://github.com/abhinavs/microrequests), please check [project homepage](https://www.abhinav.co/microrequests.html) for more and updated details.
---
# Narrative Chasm
URL: https://www.abhinav.co/narrative-chasm
Date: 2020-11-01T00:00:00+00:00
Every company and entrepreneur needs a narrative to tell to the world. A good narrative is almost as important as an excellent product.
These narratives are forward-looking. They highlight the big opportunity and why the company is poised to capture it.
However, in an attempt to create a compelling narrative, entrepreneurs often knowingly or unknowingly exaggerate the company’s strength and hide the challenges or risks.
The biggest trouble happens when everybody in the company starts believing that narrative as reality. Mid-level managers and employees fall for this more given they hear it regularly in pep-talks. Companies become over-confident, underestimate the challenges they face, neglect org culture, forget about customer experience, build unnecessary & complex features, and get into mega-hiring spree.
This lack of self-awareness and humility prevents them from achieving their real potential.
This is a **chasm** that even most of the successful companies never cross. They never become truly glorious.
---
# Peacetime
URL: https://www.abhinav.co/peacetime
Date: 2020-11-26T00:00:00+00:00
A while back, [Ben Horowitz](https://www.twitter.com/bhorowitz) wrote a [great post](https://a16z.com/2011/04/14/peacetime-ceowartime-ceo-2/) on the concept of peacetime CEOs and wartime CEOs. I recommend reading it in case you haven't read it.
We understand that companies in wartime require a military kind of approach to execution - we also admire leaders who are able to successfully lead companies in these times.
Ben has been a good wartime leader, and it is implicit in the post that he thinks it is harder to be a wartime CEO than to be a peacetime CEO. Probably that is the case. Or perhaps, we are wired to glorify war. Look at history books, and you will find that the majority of time is spent discussing wars, jumping from one winning ruler to another.
Politically, peace is a very modern phenomenon. My hypothesis is that as human beings, we don’t intuitively understand peacetime, especially when it comes to the core of capitalism - companies.[^1]
We don’t know how to manage companies in peacetime.[^2] We either look for war opportunities, artificially create war like situations, or fail to utilise peacetime to create an edge, eventually fighting to survive. No wonder, you see many great companies vanish, die a slow death, or become irrelevant because of their inability to manage peacetime effectively.
Need examples? Yahoo!, Nokia, Blackberry, MySpace, Motorola, Pan Am, AOL, Path, Digg, JetAirways, Apple of 91-97.
I believe we need to develop more appreciation for peacetime and great peacetime leaders.
Peacetime leaders, of course, have time and the liberty to make a few mistakes. However, managing a company in its peacetime, to continue driving growth at incredible pace and building a lasting company, requires an approach that is easier said than done.
- Peacetime leaders need to have a long-term hypothesis about their business. They can't afford to be reactive.
- They need to make moves and take bets which might (or might not) pay off after years of investments. Their 'experiment-feedback-learn' cycles are often long and harder to manage.
- They need to be willing to cannibalize business lines or short-term business for the longer term gain.
- Leading and rallying people in peacetime is hard. Peacetime leaders need to build empowered teams that have the freedom to fail and learn. They need to listen and observe their team to drive innovation.
- Like modern countries, they need to ensure that they create enough defence to discourage competitors from attacking them.
Personally for me, **Satya Nadella** is the best example of a peacetime CEO. A few would argue that he became the CEO when Microsoft was fighting for relevance and he is actually a wartime CEO. In my opinion, both Microsoft and Satya were self-aware of the challenges and they just proactively tackled them.
- He improved the internal culture of a 40+ year old organization that was getting bureaucratic and too competitive. It is an extremely hard, almost impossible thing to do.[^3]
- He recognized, to innovate they need to do things which they haven't done before - heavy investments in open source. Microsoft joined Linux Foundation as a high-paying Platinum Member and through VS Code, Typescript, Xamarin and Github, Microsoft has transformed its image when it comes to open source.
- Microsoft made a few big and smart acquisitions (Linkedin, Github) and took > $7 billion writedown on Nokia.
- He changed strategy to focus more on recurring revenue with Azure and Office 365 Cloud.
And result, Microsoft's valuation under him has increased from $300 billion to $1.6 trillion, i.e **more than 5x in 6 years**.
To contrast, let me give an example of Yahoo!, mostly because I was at Yahoo! at the peak of their peacetime (2005-2007) and in retrospect, I can see the mistakes it made.
- Wars of the past decade (Internet race and dot-com crash) had made it very short-sighted. It looked for short term results. As an example, it spent a lot of time building systems to effectively count the number of display ads shown instead of focusing on performance based advertising.[^4]
- It failed to innovate. A few innovative Web 2.0 companies it acquired (Flickr, Delicious) were not properly utilised.[^5]
- Yahoo!’s strategy was to become a media company. I think nothing was wrong with that. However given the CEO’s background (Terry Semel, who came from Warner Bros.) strategy was fuzzy and not appropriate for a tech-driven Internet company.
- Obsession with Google - Google featured in almost all the all-hands meetings I attended (from India). There was always a strategy to deal with Google's emergence.
Leading a company in wartime is definitely hard - it requires willingness to take hard calls, ability to handle high-stress and great reflexes to respond to every new battle that comes up.
However, in my opinion, it is harder to **successfully** lead a company in peacetime - to have empathy; to have an open mind; to have an intuition about the future; to handle ambiguity; to be patient with the bets; to know that world by default won't remember them; to resist the urge to maintain status quo and build the company that continues to *win* and lasts.
> Thanks Shikhi Shrivastava and Pathik Shah for their feedback on the drafts.
#### Footnotes
[^1]: Academia probably understands it the best, however at the moment, even most of the academicians and researchers have no other option but to operate in war mode given their funding obligations.
[^2]: For that matter, we don't necessarily always know if a company is in peacetime or wartime. And incorrect identification impacts companies more often than one would imagine - for example - a lot of startups get into peace mode when they should still be in war mode, on the other hand, a few startups continue to operate in war mode - getting kicks by creating more battlefields than they can sustain.
[^3]: Microsoft's organizational was illustrated by cartoonist and Googler, [Manu Cornet](https://www.businessinsider.in/slideshows/miscellaneous/a-google-programmer-just-published-a-book-of-hilarious-cartoons-that-shows-what-its-really-like-to-work-at-the-search-giant/slidelist/65878293.cms#slideid=65878302) in his book Goomics as follows 
[^4]: Trivia - pay-per-click model was in fact invented by Overture, which was acquired by Yahoo! in 2003. In 2004, Google and Yahoo! made a patent settlement in which Yahoo! was given ~$300 million worth of Google shares. At that time, Yahoo! also owned approx ~$600 million worth of Google stock because of their prior investment of $10 million in the year 2000. [Read more](https://www.nytimes.com/2004/08/10/business/technology-google-and-yahoo-settle-dispute-over-search-patent.html)
[^5]: To be fair, Yahoo! did try - it sponsored and spent time and money in building Hadoop which in a lot of way started Big Data revolution, it also built [Yahoo! Pipes](https://en.wikipedia.org/wiki/Yahoo!_Pipes) which let users create API mashups with a GUI. Tim O'Reilly called it as a milestone in the history of the Internet, however it never [reached its potential](https://thenextweb.com/insider/2015/06/05/a-series-of-pipes/)
---
# Elixir Plugs
URL: https://www.abhinav.co/elixir-plugs
Date: 2020-12-30T00:00:00+00:00
Of late, I have been writing some Elixir code to build an API layer for Soopr, a SaaS tool I am working on. This system needed a simplistic authentication mechanism and I ended up writing a custom Plug for it. This post explains what are plugs and how you can write one yourself.
## What is a Plug?
In Elixir world, Plug is a bit similar to [Rack](https://github.com/rack/rack) in Ruby. [Official documentation](https://hexdocs.pm/plug/readme.html) describes Plug as:
1. A specification for composable modules between web applications
2. An abstraction layer for connection adapters for different web servers in the Erlang VM
Plugs can be chained together and they can be very powerful as well as can add simplicity and readability to your code.
If I were to describe Plug, plugs are a mechanism through which either you can transform your request/response or you can decide to filter requests that reach to your controller.
In Plug/Phoenix world, `%Plug.Conn{}` in the connection struct that contains both request & response paramters and is typically called `conn`.
### Transformation
It essentially means modifying `conn` (technically, creating a copy of original `conn`) and adding more details to it. These plugs also need to return modified `conn` struct so that plugs can be chained together. Some examples of plugs are:
* [Plug.RequestId](https://hexdocs.pm/plug/Plug.RequestId.html) - generates a unique request id for each request
* [Plug.Head](https://hexdocs.pm/plug/Plug.Head.html) - converts HEAD requests to GET requests
* [Plug.Logger](https://hexdocs.pm/plug/Plug.Logger.html) - logs requests
### Filter
There are cases when you want to stop HTTP requests if they don’t meet your criteria. Example - they come from a blocked IP or more common example - don’t have required authentication details. In these cases you use such plugs. [Plug.BasicAuth](https://hexdocs.pm/plug/Plug.BasicAuth.html) is one such plug, it provides Basic HTTP authentication.
## How are plugs chained?
In Phoenix world, plugs are generally added to your `endpoint.ex` or `router.ex` modules.
```elixir
defmodule MyAppWeb.Router do
use MyAppWeb, :router
import Plug.BasicAuth
pipeline :api do
plug :accepts, ["json"]
plug :basic_auth,
username: System.fetch_env!("AUTH_USER"),
password: System.fetch_env!("AUTH_KEY")
end
scope "/api/v1/", MyAppWeb do
pipe_through :api
get "/posts", PostController, :index
end
end
```
In this example - our `api` pipeline would accept only json requests and require basic authentication. This api pipeline is then used to define a `GET /api/v1/posts` route.
## How to build your own Plug?
There are two ways in which you can write your own Plug - Function or Module.
### 1. Function Plugs
Function plugs are generally used if your plug is simple enough and doesn’t have any costly initialisation requirement. To write a function plug, simply define a function which takes two inputs - `conn` and options.
[Example](https://hexdocs.pm/phoenix/plug.html#function-plugs):
```elixir
def introspect(conn, _options) do
IO.puts """
Verb: #{inspect(conn.method)}
Host: #{inspect(conn.host)}
Headers: #{inspect(conn.req_headers)}
"""
conn
end
```
### 2. Module Plugs
Module plugs are useful when you have a bit heavy initialisation process or you need auxilary functions to keep your code readable. For a Module Plug, you need you to define following two functions inside an elixir module:
1. `init/1` where you can do the initialisation bit. It takes options as input, something that you can pass when using it in router or endpoint file.
2. `call/2` which is nothing but a function plug and takes exactly the same two parameters - `conn` and `options`
```elixir
defmodule MyAppWeb.BearerAuth do
import Plug.Conn
alias MyApp.Account
def init(options) do
options
end
def call(conn, _options) do
case get_bearer_auth_token(conn) do
nil ->
conn |> unauthorized()
:error ->
conn |> unauthorized()
auth_token ->
account =
Account.get_from_token(auth_token)
if account do
assign(conn, :current_account, account)
else
conn |> unauthorized()
end
end
end
defp get_bearer_auth_token(conn) do
with ["Bearer " <> auth_token] <- get_req_header(conn, "authorization") do
auth_token
else
_ -> :error
end
end
defp unauthorized(conn) do
conn
|> resp(401, "Unauthorized")
|> halt()
end
end
```
This is taken from an actual plug which I wrote for Soopr (I have just changed the names). Though I didn’t have any heavy initialisation requirements, I decided to use module way of writing so that I can define a couple of private helper functions. In this example:
1. `init/1` function takes options, however does nothing with it.
2. `call/2` function takes conn and options as input
3. Private function `get_brearer_auth_token/1` takes `conn` as input and tries finding `auth_token`.
4. From `auth_token` we try finding an account. If we find the account, we add in our `conn` so that it is accessible to downstream plugs and controller functions.
5. In case we don’t find `auth_token` or `account` we respond with `401` and halt the request, `unauthorized/1` function takes care of that.
### Interesting Usecases
Here are a few interesting problems which you can possibly solve using your own custom plugs.
1. Firewall - block traffic from barred IP addresses or clients.
2. Last Seen - in messenger apps, last seen is maintained separately, using a plug you can update users' last seen value.
3. Throttle - throttle requests depending upon limits set by you or pricing plans.
4. Circuit Breaker - in case your downstream backend systems are facing trouble, you can decide to prevent traffic from creating more trouble.
### A few words about Elixir
Writing code in Elixir and Phoenix is fun and the best part is I feel very productive yet understand the whole pipeline (unlike other frameworks like Ruby on Rails or Django that have a lot of inbuilt magic). I also feel happy that 13 years after first learning Erlang, I am finally using Erlang's elegant way of building systems in production.
Do give Elixir a try.
---
# Moonwalk
URL: https://www.abhinav.co/moonwalk
Date: 2021-01-08T00:00:00+00:00
When I first built this website ([abhinav.co](https://www.abhinav.co)), I used custom CSS and HTML. However, with every new project getting added, I realized I was spending more time in managing the website code than the actual website content. My subconcious mind also delayed regular blogging and demanded that I create a better website to evoke the desire to write. And like a slave without any choice I accepted.
I had some experience with Jekyll and wanted to use it again. I spent numerous hours trying to find the perfect theme which matched elegance as well as simplicity and in the end decided to write my own custom theme. It was a fun project - I enjoy UX and UI design and considered this as a great opportunity to try out my own opinions about good design.
The outcome is Moonwalk - a fast and minimalistic blog with clean dark mode.
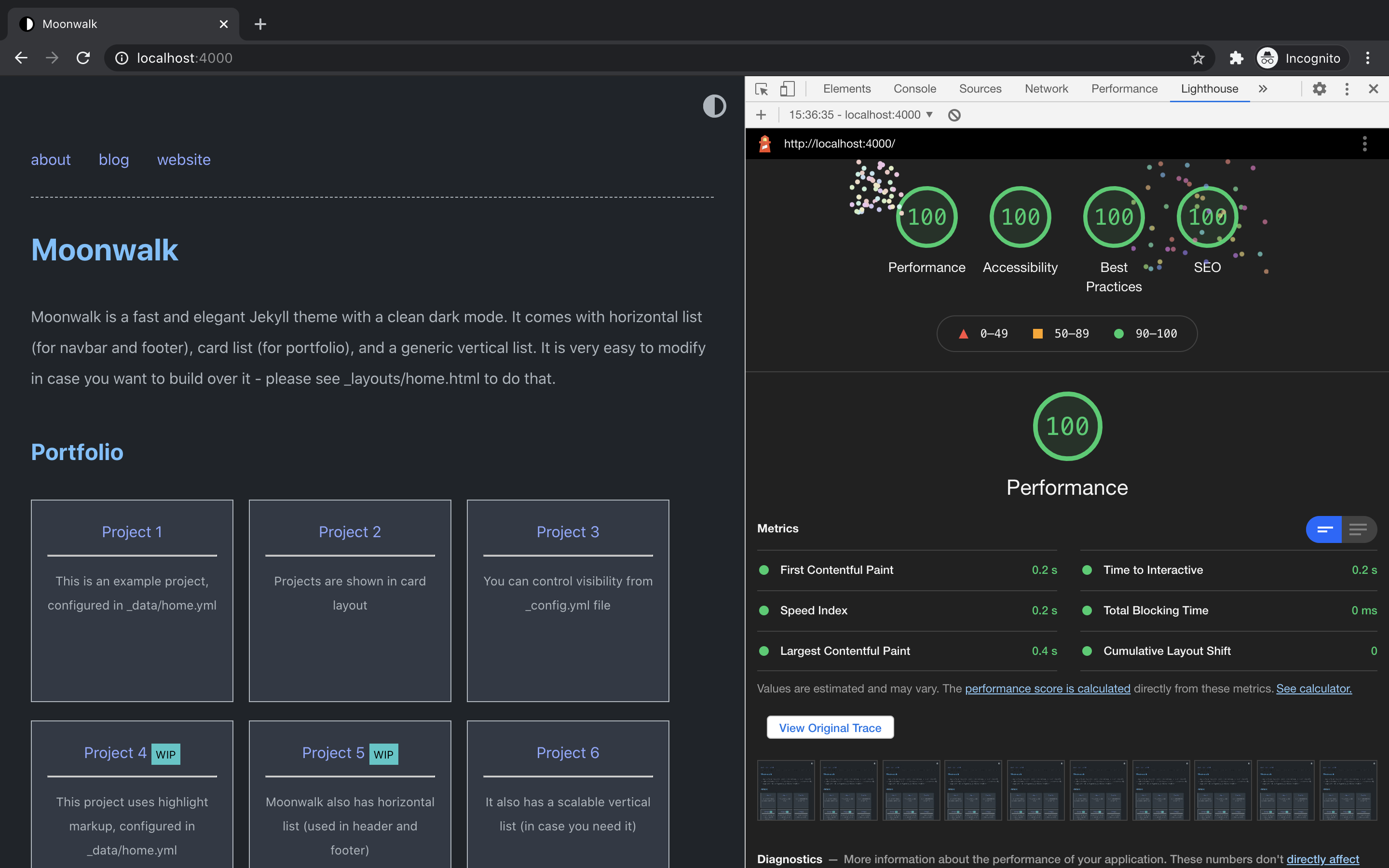
 I wanted moonwalk to be very fast and made choices to make it very performant. I took [no style please!](https://github.com/riggraz/no-style-please) as a base, a wonderful theme with almost no CSS and customized it heavily to express my design. I avoided the temptation to add any css or javascript frameworks and explicity made the blog text heavy than image heavy. And it's not a surprise that Moonwalk has a perfect 100/100 Lighthouse score.
If you want to see a demo - this very website is the best example of it.
Do try [moonwalk](https://github.com/abhinavs/moonwalk) for your next project.
I wanted moonwalk to be very fast and made choices to make it very performant. I took [no style please!](https://github.com/riggraz/no-style-please) as a base, a wonderful theme with almost no CSS and customized it heavily to express my design. I avoided the temptation to add any css or javascript frameworks and explicity made the blog text heavy than image heavy. And it's not a surprise that Moonwalk has a perfect 100/100 Lighthouse score.
If you want to see a demo - this very website is the best example of it.
Do try [moonwalk](https://github.com/abhinavs/moonwalk) for your next project.
## Features
* Light & dark mode with theme switcher
* Vertical list, horizontal list, card list
* Landing page with navbar, footer, portfolio
* Fast (very minimal CSS) - 100/100 on performance, accessibility, best practices and SEO, please see [Lighthouse Report](https://raw.githubusercontent.com/abhinavs/moonwalk/master/_screenshots/lighthouse-report.png) for more details
* Responsive and mobile friendly
* SEO optimized (uses [Jekyll SEO Tag](https://github.com/jekyll/jekyll-seo-tag))
* RSS feed (uses [Jekyll Feed](https://github.com/jekyll/jekyll-feed))
* Easy to extend
* Fully compatible with [GitHub Pages](https://pages.github.com/) (see [GitHub Pages installation](#github-pages-installation))
### Lighthouse Score
## Quick Installation
1. Fork this repository.
2. `cd moonwalk`
3. `bin/bootstrap`
## Starting Server
`bin/start` - development server will start at http://127.0.0.1:4000
## Deployment
Moonwalk can be easily deployed on all the cloud providers (AWS etc.), and on static website hosting services like Netlify & Vercel. You can also use this button to do one click deploy
[](https://app.netlify.com/start/deploy?repository=https://github.com/abhinavs/moonwalk)
If you want to use Moonwalk as a gem or use Github Pages, please see [this page](https://github.com/abhinavs/moonwalk/blob/master/github_pages.md)
## Customizing
You can edit `_config.yml` file to customize your blog. You can change things such as the name of the blog, the author, the appearance of the theme (light, dark or auto), how dates are formatted, etc. Customizable fields should be straightforward to understand. Still, `_config.yml` contains some comments to help you understand what each field does.
### Customize the menu
In order to add/edit/delete entries in the home page, you can copy the `home.yml` file inside `_data` folder. Through that file you can define the structure of the menu and add data for navbar, footer, portfolio or simply remove all of that and use simple blog layout. Take a look at the default configuration to get an idea of how it works and read on for a more comprehensive explaination.
The `home.yml` file accepts the following fields:
1. Vertical list
- `entries` define a new unordered list that will contain menu entries
- each entry is marked by a `-` at the beginning of the line
- each entry has the following attributes:
- `title`, which defines the text to render for that menu entry
- `url`, which can either be a URL or `false`. If it is `false`, the entry will be rendered as plain text; otherwise the entry will be rendered as a link pointing to the specified URL. Note that the URL can either be relative or absolute.
- `post_list`, which can be `true` or `false`. If it is true, the entry will have all posts in the site as subentries. This is used to render your post list.
- `entries`, yes, you can have entries inside entries. In this way you can create nested sublists!
2. Card list - cards are used to showcase portfolio projects. Please see `project_entries` in `_data/home.yml` file
- each entry is marked by a `-` at the beginning of the line
- each entry has the following attributes:
- `title` defines the header of the card
- `desc` is the body of the card
- `url` is a relative or absolute link which this card can point to.
- `highlight` in case you want to highlight something, keep the text short though
3. Horizontal list - moonwalk uses horizontal lists to create navbar and footer. Please see `navbar_entries` and `footer_entries` in `data/home.yml` file
- each entry is marked by a `-` at the beginning of the line
- each entry has the following attributes:
- `title` defines the header of the card
- `url` is a relative or absolute link which this card can point to.
### Pro tips
1. Moonwalk has 3 in-built layouts:
- post - for content
- blog - for listing blog posts
- home - for landing page
you can change your `index.md` file to use either home or blog layout.
2. It is extremely easy to tweak the color scheme.
For light mode, customize these css variables
```css
html {
--bg: #fff;
--bg-secondary: #f8f9fa;
--headings: #000;
--text: #333;
--links: blue;
--highlight: #ffecb2; // light yellow
}
```
For dark mode customize these css variables
```css
@mixin dark-appearance {
html, body {
--bg: #1f242A;
--bg-secondary: #323945;
--headings: #3D9970;
--text: #adb5bd;
--links: #91a7ff;
--highlight: #ffd43b;
};
}
```
## Contributing
Bug reports and pull requests are welcome on [GitHub](https://github.com/abhinavs/moonwalk).
## Development
To set up your environment to develop this theme, run `bundle install`.
Your theme is setup just like a normal Jekyll site! To test your theme, run `bundle exec jekyll serve` and open your browser at `http://localhost:4000`. This starts a Jekyll server using your theme. Add pages, documents, data, etc. like normal to test your theme's contents. As you make modifications to your theme and to your content, your site will regenerate and you should see the changes in the browser after a refresh, just like normal.
When your theme is released, only the files in `_layouts`, `_includes`, `_sass` and `assets` tracked with Git will be bundled.
To add a custom directory to your theme-gem, please edit the regexp in `moonwalk.gemspec` accordingly.
## Acknowledgement
This theme's original base is [no style please!](https://github.com/riggraz/no-style-please) theme created by [Riccardo Graziosi](https://riggraz.dev/) - many thanks to him for creating a wonderful theme with nearly no css.
## License
The theme is available as open source under the terms of the [MIT License](https://opensource.org/licenses/MIT).
---
# Cookie
URL: https://www.abhinav.co/cookie
Date: 2021-03-06T00:00:00+00:00
I recently launched [Soopr](https://www.soopr.co), a set of easy to use tools for your static websites. While building Soopr, I got fascinated with the idea of using a static site as landing website, and using markdown to power additional supporting pages and blog posts. And the outcome is Cookie.
Cookie is a Jekyll and Tailwind CSS based static website that makes the whole process of creating and launching landing websites extremely easy. With its responsive and mobile friendly pages, integrated blog, additional pages and [Soopr](https://www.soopr.co) integration, it can help you focus on building your product than landing website.
## Demo
You can see demo app deployed [here](https://cookie-demo.netlify.app/)
## Why Jekyll?
Jekyll is a static website generator - what it means is that in production, your site will be faster because it has been converted into HTML pages while deployment. Another reason is that by separating your landing website from your app website, your app servers get comparatively free and can boost performance for your regular customers. I chose Jekyll also because it is one of the most stable and simple static website generator frameworks and thus reduces complexity.
Cookie also uses Tailwind 2.0 which is a utility first CSS framework, and makes the process of iterating on homepage a lot easier.
## Features
* Well-designed landing page
* Responsive and mobile friendly
* Additional pages like about us, terms of service & privacy policy
* Integrated blog, write content in markdown format
* Easy to customize using Tailwind CSS
* Fast and performant website
* SEO optimized
* RSS feed
* Easy to deploy on platforms like Heroku, AWS, Netlify & Vercel. One-click deploy on Netlify is also possible
* [Soopr](https://wwww.soopr.co) integrated - easy to customize share & like buttons, shorten URLs and website analytics
## Installation
1. Fork this repository.
2. `cd cookie`
3. `bin/bootstrap`
## Starting Server
`bin/start` - development server will start at http://127.0.0.1:4061
## Customizing
1. You can customize landing page by modifying index.html in root directory.
2. You can customize other website pages by modifying files present in `_pages` directory. You can add more pages too - you will be able to directly link to them using filename. Don't forget to change Terms & Privacy Policy.
3. You can write blog posts in `_posts` directory. It's a regular Jekyll blog, and Tailwind Typography for better blog formating and code syntax highlighting is already included.
4. You should also checkout `_config.yml` in root directory, and add relevant details. Many of them are used for SEO purposes.
5. You should also add favicons in `custom-head.html` present in `_includes` directory. You can use [RealFaviconGenerator](https://realfavicongenerator.net/).
6. You can customize image assets in `assets/img` directory.
7. You will have to hook the 'Work with Us' form present on main page with a real backend.
8. [Font Awesome](https://fontawesome.com/) is also integrated, to add any icon in your HTML files, you can refer to the website
## Deploy Instructions
Website can be easily deployed on all the cloud providers (AWS etc.), and on static website hosting services like Netlify & Vercel. You can also use this button to do one click deploy
[](https://app.netlify.com/start/deploy?repository=https://github.com/abhinavs/cookie)
## Contributing
Bug reports and pull requests are welcome on GitHub at [https://github.com/abhinavs/cookie](https://github.com/abhinavs/cookie).
## Acknowledgement
Cookie uses landing page provided by [Tailwind Starter Kit](https://www.creative-tim.com/learning-lab/tailwind-starter-kit/presentation) - thanks for providing an amazing landing page under MIT License. Initial code was also inspired by [Jekyll TailwindUI](https://github.com/chunlea/jekyll-tailwindui)
## License
This project is available as open source under the terms of the [MIT License](https://opensource.org/licenses/MIT).
---
# Hierarchy of Employees' Needs
URL: https://www.abhinav.co/hierarchy-of-employees-need
Date: 2021-03-12T00:00:00+00:00
A lot of content is available on the importance of company culture, and how company culture can make or break a company.
What is least talked about are things that motivate the team - not the team as a whole, but individual team members. Although leaders know that different things motivate different people, more often than not, we lead with intuition without any concrete framework.
I believe as employees in a company, we all have a hierarchy of needs, and different people could be at different levels. Understanding at what level a person is can help you customize the pitch, job, or role and create a better growth path for them.
Here is my take on the hierarchy of needs in the context of organizations and employees. These needs map almost one to one with [Maslow’s Hierarchy of Needs](https://www.simplypsychology.org/maslow.html). Moreover, all of these levels continuously overlap with each other, however, a certain amount of
need must be met before a person completely migrates to the higher level.
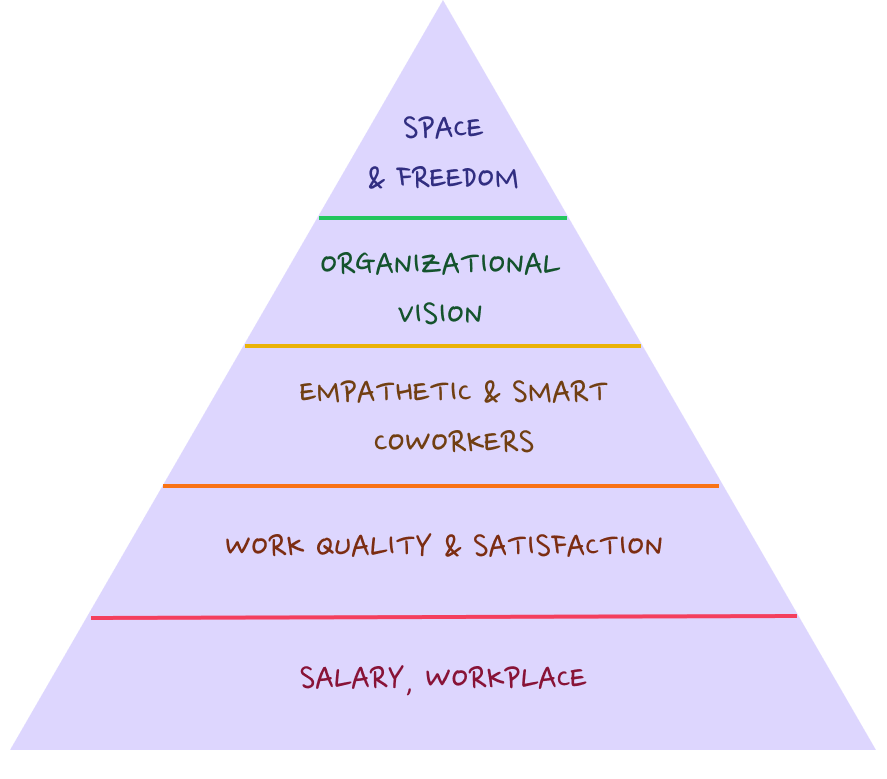{:class="img-responsive"}
1. **Salary, Workplace** - This is one of the basic needs people have. A person without a job would be hardly inspired by your vision or pitch and more often than not, choose a company with higher pay and facilities. Of course, you will find people that don’t worry a lot about these things, however, either they have minimized their needs a lot or their such needs are already taken care of.
2. **Work Quality & Work Satisfaction** - Once the basic needs are taken care of, people start looking at the quality of their work and the satisfaction they derive from that. Leaders should strive that people at this level don’t find their job monotonous and their work challenges them. If it is hard to change the work, the focus should be on creating forums for learning and sharing knowledge.
3. **Empathetic & Smart Coworkers** - This is one of the social needs we have as human beings. People look to work and collaborate with smart & empathetic coworkers that can make the work easy, interesting, and fun. In addition to hiring well, as a leader, you should strive to create a transparent culture. This makes information arbitrage difficult that in turn prevents politics creeping into the org. Another thing to ensure is that silos are not formed - silos may provide you speed, but not velocity.
4. **Organizational Vision** - People that get to this stage look at the impact of their work. They are trying to feel not just satisfied but accomplished. To motivate and retain these folks, as a leader, you need to communicate your vision for the organization and get real buy-in from them. On the other hand, if you find people who ideally should be at this level (example - senior executives, early employees) and don’t necessarily buy the vision, don’t hesitate to weed them out.
5. **Space & Freedom** - This is the self-actualization phase in an employees’ hierarchy of needs. Retaining and motivating people that reach this level is the toughest. They may completely believe in the org’s vision and maybe the cultural ambassadors of the company, however, they will leave if they don’t get enough space and freedom to operate or feel micromanaged. Simplest framework for leaders dealing with people at this level - do you trust the person and their judgment? if yes, create a few guardrails and give them freedom & space to operate under those guardrails. If your answer is no, probably it is best for the company and them that they leave.
Leading people is hard. I hope this framework will provide a bit more structure to the intuition and help you become a more effective yet empathetic leader.
---
# Why build Static Websites?
URL: https://www.abhinav.co/static-websites
Date: 2021-03-19T00:00:00+00:00
A new technology trend emerged a few years ago - static websites & static website generators. I saw that, even created [my website](https://www.abhinavsaxena.com/) using one of the frameworks, but I didn't think much about it.
And then I got busy - between managing people and striving to meet quarterly OKRs, I didn't notice the emergence of platforms like [Netlify](https://www.netlify.com/) and [Vercel](https://vercel.com/). I also didn't immediately see the benefits of using static websites.
However, sometime last year it clicked like a light bulb. During that time, I was trying to create a theme for my own blog as well as build a web app for one of my ideas. I saw the difference in terms of building and managing the landing page and other associated static pages like about, terms, etc. Moreover, I saw [Google Lighthouse](https://developers.google.com/web/tools/lighthouse/) scores of both the sites and was amazed. Static websites were not only easy to build and manage, but they were also very performant.
This is the time when I also noticed that I was not the only one who had noticed this. Most of the tech companies had already started separating their landing websites and blogs from their dynamic websites (tool, dashboard, etc.) For example - I realized Stripe's [landing website](https://www.stripe.com) and their [dashboard](https://dashboard.stripe.com) were behind two separate subdomains. Buffer's [landing website](https://buffer.com/) and [web app](https://login.buffer.com/login) were separate too.
Now I know why this separation makes sense:
- Landing websites generally have marketing content, information about the company, and a blog. There are a finite number of pages, content (generally) does not depend upon who is viewing it and thus can be statically generated when the website is deployed instead of dynamically getting created whenever users are visiting the site. In such cases, the static site will be extremely fast because it has been ‘compiled’ into HTML pages during deployment. For example - Buffer's [about page](https://buffer.com/about) loads and renders pretty quickly.
- This also means that your dynamic website (which is behind a login) is isolated and its server (typically written in Python, Ruby, Node, Java) can focus on handling logged-in users and actual business logic. This separation of concern is very powerful (akin to microservices) and means each of these websites (static and dynamic) can operate and scale independently.
- If you think this in terms of the marketing funnel - the number of users coming to your website and blog will be way higher and depending upon the conversion rate only part of these users would convert into actual customers (i.e. they will log in and transact). By keeping the two websites separate, you ensure that the performance of one website is not impacted by another website. In fact, the static website can completely be cached by servers and browsers
- This separation also saves cost. Your dynamic website is no longer busy handling marketing traffic.
This stack is being popularly called [JAM Stack](https://jamstack.org/) (disclaimer - this page uses a lot of Jargons, but the idea and implementation are not very complicated).
While building the landing website for [Soopr](https://www.soopr.co), I decided to extract everything into a separate easy-to-use landing website template. I not only wanted to make my landing website very fast, but I also wanted to use markdown to power additional supporting pages and blog posts.
And the outcome is [Cookie](https://github.com/abhinavs/cookie). It is completely open-sourced and free to use. You can read more about it [here](/cookie) and check the demo [here](https://cookie-demo.netlify.app/). Give it a try for your next project.
---
# Growth Debt - Part 1
URL: https://www.abhinav.co/growth-debt-part-1
Date: 2021-03-28T00:00:00+00:00
Once upon a time you were a bunch of folks (hopefully with complementary skills). You decided to build a company together. You worked on the product - designing it, building it and selling it.
And then you started growing.
You needed more people to help you out in specific areas and you started hiring. Probably your backend systems didn’t hold up and you hired a few backend engineers. Or perhaps, you wanted to build iOS and Android apps and you got people who had experience with that. You got a few product managers too.
You continued growing and you continued hiring.
And then you noticed - your shipping speed has slowed down.
You started comparing shipping speed with the early days, and attributed the slowing down to lack of intent or commitment of people in your team. However, if you had hired right, amongst other reasons there may be a few genuine reasons that can’t be immediately fixed. These genuine reasons are often ignored.
Some of them could be
1. You had made certain assumptions while building your pre-customer and pre-revenue product and those assumptions are no longer valid. You didn’t (rightly so) focus on building a generic system. With existing product & code you are now trying to handle a myriad number of cases, and that is slowing down your development of new features.
2. You had less number of customers and their needs were also confined to the initial product you had built. Now with a growing set of customers with varied use cases and workflows, each release requires more & extensive testing.
3. You might have also acquired users across the timezones and your team now can’t afford to bring systems down for maintenance activities. They need to write extra code, devise a predictable sequence of steps that doesn’t impact any customer across any timezone.
4. You didn’t invest in automating or/and building documentation early on (perhaps rightly so), however, now onboarding each new member in the team is getting costlier. They demand energy from existing team members and at the same time, still may not get productive quickly. In the worst case, they might also make a lot of mistakes because of this and that keeps your team busy.
I classify these genuine reasons as Growth Debt. Every company that grows (in terms of business and/or age) will have it.
Analogy wise, growth debt is like life-style diseases you get as you grow old. Some companies have a higher propensity of acquiring it early on.
If you don’t spend time regularly to identify and pay, it can soon start damaging your company and its growth.
In the next part, we will cover another heavily discussed but often misunderstood term - Tech Debt.
---
# Growth Debt - Part 2: Tech Debt
URL: https://www.abhinav.co/technical-debt-growth-debt-part-2
Date: 2021-03-30T00:00:00+00:00
Technical debt is a scary term. It is also one of most misunderstood terms. Here is my pragmatic take on it.
You may have:
1. Badly written code, but it might not impact you at all (in terms of maintenance cost, bugs or growth).
2. Or you may have portions of code that might be slowing you down because of code quality, an increasing number of new assumptions and/or wrong and invalid old assumptions.
I would not classify **1** as technical debt, it’s just bad code. Engineers in the team might find it irritating, however there’s no real interest to be paid on it.
However, **2** is techinal debt.
Engineers often get all the blame for the tech debt, however, in reality, it is a function of clarity, code quality, and validity of assumptions made.
Analogy wise, technical debt is no different from credit card debt, while some is even at times beneficial, but eventually it needs to be paid off.
To keep tech debt in check, you need to check the direction your company is taking & recalibrate your assumptions (present in your code) keeping current and at least a couple of future years requirements in mind. If you are a very early stage company and still figuring out the direction, then this period could be a couple of quarters too. Once you have done that, you need to see if you need to pay the debt right away or you are willing to pay the debt at a later stage.
This is where experience is helpful, because fixing code that is just bad, or paying debt prematurely might stop you from working on something more important. On the other hand, not allocating time to pay tech-debt (with compounding interest), will slow down your company’s growth considerably. You need to understand these trade-offs and make an explicit decision.
In summary, have a regular cadence for
1. Spending time to understand, in your context, what is bad code and what is tech debt
2. Understanding the impact of a particular tech debt has today and in the future. Understand the effort and return of paying the tech debt a) today b) a quarter later c) a year later.
3. Recalibrating your assumptions (baked inside your code). They are the source of most of the tech debt.
---
This is part 2 of my post on [Growth Debt](/growth-debt-part-1). I have also previously written about a few similar topics here:
1. [Growing Startups and Tech Debt](/growing-startups-and-tech-debt)
2. [Speed](/speed)
3. [How to engineer an MVP](/how-to-engineer-an-mvp)
4. [Speed and Quality](/speed-vs-quality)
---
# Gurgaon
URL: https://www.abhinav.co/gurgaon
Date: 2021-04-15T00:00:00+00:00
I recently realized I have spent more time living in Gurgaon than in Bangalore.
In 2011, when I first told one of my friends that I was moving to Gurgaon - he laughed at me. He had stayed in Gurgaon for a year and he absolutely hated it. As per him, there was no public transportation system, no chai-shops, almost no infra - just malls and offices.
And he was right. However, what troubled me the most was the weather. My first winter and my first summer in Gurgaon were terrible. The unfortunate thing was that these two seasons covered ten months out of twelve, and I found only March & November a little bearable.
No wonder, I didn’t like Gurgaon, and I hoped to move back to Bangalore ‘as soon as possible’. I now have spent 9 years here and have come to like Gurgaon. Here are some of my reasons
- Gurgaon is a comparatively smaller place. I can technically live in any part of Gurgaon, and still, my wife, my daughter, and I can hope to reach our respective offices and schools in under 30 minutes
- Delhi Airport is 45 minutes from my home.
- Some of the best schools in the country are in Gurgaon.
- Gurgaon has been improving its infra every day - this is one area where it is really commendable at the speed at which Gurgaon has transformed itself. Almost all choke points now either have fly-overs or they are being built now. And they don’t take years to build.
- Metro, Rapid Metro, and bus service are an added advantage. (Though, to be honest, not enough people use them.)
- There are enough job opportunities; the number of companies, startups and unicorn startups are increasing at a healthy pace.
- Moreover, offline to online startups find Gurgaon a lucrative place to start their operation and provide their best services because of the smaller size and spending power of the population.
- My parents feel more comfortable in Gurgaon (in fact, I think, they like it here more than our hometown) I think language (i.e. Hindi) play a huge role in their case. They have friends in the society with diverse backgrounds. A lot of people from Delhi and surrounding areas have also settled in Gurgaon after retirement.
- You don’t have to wait a lot for cabs, surge, AFAIK, is also bounded because of government regulation.
- This is specific to me - I find it comfortable to be at a place where everybody around me is not a software engineer or into tech companies - helps me in anonymity.
- Proximity to Delhi, Noida, and other NCR cities help - my hometown is well connected via trains starting from Delhi.
- There are enough tourist places that you can go to over a weekend, including mountains, national parks, forts and pilgrimage towns.
- It might be just me, however, I don’t find Gurgaon unsafe or pretentious (I mean, it is as unsafe and pretentious as any other Indian metro city is)
Weather-wise Gurgaon is still very bad. Pollution is a big problem. And yet, the thought of moving out of Gurgaon and settling in a place like Bangalore unsettles me. I guess I don’t hate it anymore.
---
# Scoop
URL: https://www.abhinav.co/scoop
Date: 2021-05-23T00:00:00+00:00
[Sinatra](http://sinatrarb.com/) is a Ruby framework that helps you quickly create web applications, APIs and microservices. Its minimalism not only attracted a lot of developers, but it has also inspired [Flask](https://flask.palletsprojects.com/en/2.0.x/) in Python and [Express](https://expressjs.com/) in Node.js
Almost a decade ago, I used Sinatra to build [pincodr](https://pincodr.apiclabs.com), [schedulr](https://github.com/abhinavs/scheduler_service/), [webhooks](https://github.com/abhinavs/webhooks) and [mudra](https://github.com/abhinavs/mudra). They had gotten stale because I didn't update them to latest stack.
This year, I decided to reboot pincodr. I spent time finding the right stack, tried building it in Phoenix/Elixir and [Pliny](https://github.com/interagent/pliny) in Ruby. However, in the end, I decided to stick to Sinatra, because I wanted to avoid rewrite and realized it was still a good choice.
Upgrading Sinatra and other packages was an easy process, however, I found myself struggling setting up production infra. It took me 3-4 days, just to sort out my deployment process as well as setting up the server. To save time for my next projects and to possibly help others, this weekend I spent some time extracting it as a bolierplate project called Scoop.
 Scoop uses
1. [Corneal](http://thebrianemory.github.io/corneal/) to make scaffolding models, controllers and views easier
2. ActiveRecord as database ORM
3. Capistrano for deployment
4. Puma as app server
5. Nginx as a proxy server
In addition,
1. it is also JSON API ready with JSON, CORS and JSONP support already enabled,
2. has a rails like console, and
3. comes up with example script and rake task that can be used to perform tasks that load the environment
You can start using Scoop by [forking this repository](https://github.com/abhinavs/scoop/fork). Scoop's [README](https://github.com/abhinavs/scoop/blob/master/README.md) has detailed steps to set up development and production systems as well as the deployment process.
Do give Sinatra & Scoop a try.
---
# Web3 - new yet old
URL: https://www.abhinav.co/web3-and-the-chasm
Date: 2021-11-07T00:00:00+00:00
Consider these questions:
- How did stock exchanges around the world originate?
- Why do governments allow them to function when they resemble gambling?
- What steps do governments take to keep them relatively safer options for investors?
I think the history of stock markets and these questions are tied to the new web3/crypto/DeFi and its future. After all, promises of shares and tokens are almost the same - communal ownership.[^1]
[Dutch East India Company](https://en.wikipedia.org/wiki/Dutch_East_India_Company) was a special company. It was the first company to issue shares to the general public. Company had a big mission and required a lot of investment. At the same time, the possibility of lucrative dividends was high. As a result, the company's and its investors' incentives were aligned.
This was the start of public companies. Quite soon people started trading their shares in the companies. Again incentives were aligned - folks with shares could get liquid money whereas the new shareholders could earn from dividends. Gradually, people were making more money by trading shares than from dividends. They would buy shares at a lower price and sell it to others at a higher price.
People started forming narratives about the companies, they also started studying financial data better to supplement the narrative. However, as it happens in the world, a lot of fraud mechanisms also emerged.[^2]
Now, many of these companies were really **important for the economy**. Some were developing modern infrastructure and hence governments started creating regulations to protect both companies and investors from these frauds. Today, while fraud has not gone completely to zero, stock exchanges are relatively safer and well-regulated.
If you see, a lot of web3 promises seem to be exactly the same as companies of earlier generations promised via shares.
However, there is very little regulation - well, that's intentional, after all decentralization is a key foundational pillar and any form of government regulation will be seen as the defeat of the original goal.
However, there's a big [chasm](https://en.wikipedia.org/wiki/Crossing_the_Chasm) that web3 still needs to cross[^3].
{:class="img-responsive"}
From this perspective I see following four distinct scenarios playing out:
1. Status Quo - web3 continues to operate without any regulation. Community self organizes and ensures that its true promise is fulfilled.
2. Governments get involved - the progressive ones try regulating it accordingly, and a few others ban them. Gradually, it gets to the balance that helps it grow, but with a few compromises.
3. Big VC firms, large companies, early believers and lobbyists keep pushing the narrative and pump in users and money. It becomes too big to fail and crosses the chasm. Governments don't regulate it at all because of various reasons (including political ones)
4. Bubble bursts. Everybody except true believers leaves. Chaos settles a bit, and these believers then create infra and use cases that help web3 cross the chasm.
Future is unpredictable. Narratives are linear and have survivor bias. What happens in the world is chaotic and non-linear. Even in web3, pragmatically speaking, a bit of everything will happen.
I do think that web3 tech, while still in its infancy, is quite neat. However, it has a long way to go. I just hope greed, fraud and associated chaos doesn't hinder web3 from reaching its full potential.
## Footnotes
[^1]: To be honest, tokens are in a lot of ways better because they are Internet native, are programmable with smart contracts and a lot more capabilities.
[^2]: A few simple fraud mechanisms were stealing share certificates, exaggerated narratives, pump and dump etc. Surprisingly many of them, in some form, exist in the web3 world too.
[^3]: Web3 critics say that cryptocurrencies haven't solved any solid use cases even after a decade of existence. Web3 believers however feel that it is still in the infrastructure creation stage, and interesting use cases will be built when the right infra is in place.
---
# Designing Microservices
URL: https://www.abhinav.co/designing-microservices
Date: 2022-08-07T00:00:00+00:00
I was recently asked about considerations while migrating to microservices architecture. While I believe not every company needs microservices, they can be really useful in scaling your org and systems.
Here are some of the top things I would keep in mind:
1. **Abstraction** - how well a problem is abstracted so that it doesn’t leak its core business rules to other services, at the same time does only one or two things.
2. **Independent DB(s)** - doesn’t share its database with other microservices. One micro-service, however, definitely can use multiple databases.
3. **Latency and number of microservices that hit in a flow** - this should ideally be limited to a specific number. P95, P99 latency, and error rates should be tracked and monitored.
4. **DAG** - there’s no circular dependency, and the relationship between microservices is ‘Directed Acyclic Graph’. This will keep dependencies, latencies, and complexity in check.
5. **Classification between core and auxiliary services** - the idea is if any of the auxiliary services die, users should face a degraded experience but no downtime.
6. **SDK** - build SDK that microservices can use to call other microservices. The idea is that this SDK becomes a core library with its inbuilt logic around logging metrics and handling degraded behavior (constructs like circuit breakers)
7. **Platform Services & Modules** - in addition, a lot of duplicated code across microservices should be pulled out and abstracted either as a supporting service or library (ex. locking, scheduler - no business logic though, connection pooling, throttling, analytics logger)
8. **Team** - take into consideration how your org structure would evolve in the next 2-3 years, the kind of product and platform teams you would have, and ensure no microservice is shared between teams.
---
# Data science libraries in Python and Elixir
URL: https://www.abhinav.co/data-science-python-vs-elixir
Date: 2022-10-04T00:00:00+00:00
Data science in Elixir is maturing at a rapid pace. This post lists data science libraries in Python along with their Elixir equivalent.
### Notebooks
- Python: Jupyter
- Elixir: [Livebook](https://livebook.dev)
### Numerical Analysis
- Python: NumPy
- Elixir: [Nx](https://hexdocs.pm/nx/Nx.html)
### Traditional Machine Learning
- Python: scikit-learn
- Elixir: [Scholar](https://github.com/elixir-nx/scholar)
### Deep learning
- Python: PyTorch / TensorFlow
- Elixir: [Axon](https://hexdocs.pm/axon/Axon.html)
It is also possible to use pre-trained models, you can use [AxonOnnx](https://hexdocs.pm/axon_onnx/AxonOnnx.html) for it.
### Data analysis
- Python: Pandas
- Elixir: [Explorer](https://hexdocs.pm/explorer/Explorer.html)
Explorer is built on top of polars library which is a lightning fast DataFrames implementation in Rust.
### Data presentation and visualization
- Python: Plotly Express / matplotlib
- Elixir: [VegaLite](https://hexdocs.pm/vega_lite/VegaLite.html)
VegaLite is Elixir bindings to Vega-Lite, a high-level grammar of interactive graphics.
### Network and geographic visualization
- Python: NetworkX (network), Folium (geo)
- Elixir: no equivalent so far
### Pipelines and orchestration
- Python: tf data, DataLoader
- Elixir: [Broadway](https://hexdocs.pm/broadway/introduction.html) and [Flow](https://hexdocs.pm/flow/Flow.html)
Elixir runs over Erlang VM called BEAM, and hence by design can work better than Python processing data in concurrent and fault-tolerant manner.
### Domain specific
For custom domains like NLP, computer vision and signal processing, Elixir libraries are still being worked upon.
---
# Notes on CBDC
URL: https://www.abhinav.co/notes-on-cbdc
Date: 2022-10-09T00:00:00+00:00
RBI has recently published a concept note on Central Bank's Digital Currency (CBDC) - it is available to read [here](https://rbidocs.rbi.org.in/rdocs/PublicationReport/Pdfs/CONCEPTNOTEACB531172E0B4DFC9A6E506C2C24FFB6.PDF).
I glanced through it and found it pretty interesting. At a personal level, I'm quite hopeful that a well-implemented CBDC can marry the benefits of cash with current pseudo-digital money.
### Why CBDC
At the moment ~3% of GDP is spent on printing, distributing, and securely storing cash. Moreover, India has around 15-30% of its GDP as a shadow economy (not all of the shadow economy is illegal, but much of it is)
Digital money in its current form (credit card, UPI) has too many entities in the middle to solve for trust. As a result, these entities charge ~2% of the transaction cost from the merchant (which essentially gets passed to customers)
I also believe, a well-implemented CBDC also has a shot to replace USD as the reserve currency of the world. China has already made some progress in implementing digital Yuan (eCNY) - AFAIK, it is primarily targeting transactions between banks (rightfully so)
China's progress is one of the key reasons why India and RBI are also so keen on CBDC
### CBDC & its implementation
Introducing CBDC should not mean that banks lose their relevance, however, it should mean they do high-order things more efficiently. As an example, they should still be the ones doing KYC, however, their recon & settlement process should be way more efficient because of CBDC.
RBI's concept note on CBDC distinguishes between retail (CBDC-R) and inter-banking entities (CBDC-W) and their respective implementation details.
I think,
- CBDC can be implemented without using blockchain and yet can be distributed with no single point of failure (think about how SSL/HTTPS certificates work)
- Direct benefit transfer (DBT) scheme launched by the govt could be more efficient with smart CBDC
**TODO: update with the design I think can work without blockchain**
### Further Reading
1. [Deepening of Digital Payments Report](https://rbidocs.rbi.org.in/rdocs//PublicationReport/Pdfs/CDDP03062019634B0EEF3F7144C3B65360B280E420AC.PDF) (January 2019) - it was written by a committee that worked under the chairmanship of Mr Nandan Nilekani.
2. [Central Bank Digital Currency – Is This the Future of Money](https://youtu.be/xoXA_mVJ504) - another interesting speech by Mr. Rabi Sankar, Deputy Governor, RBI. He talks about the difference between currency & money, then presents RBI's viewpoint. [Transcript](https://www.rbi.org.in/Scripts/BS_SpeechesView.aspx?Id=1111)
---
# addy - like apt install, but for people
URL: https://www.abhinav.co/addy
Date: 2025-07-21T00:00:00+00:00
Every company has a version of this problem.
A new engineer joins. Someone sends a Slack message to whoever manages the servers. That person sets up access when they find the time - creating accounts, copying keys, updating permission files. All done by hand, all from memory. When that engineer leaves, most of this gets undone. Some of it doesn't - old access quietly lingers on servers nobody thinks to check.
Some teams give up and share a common `deploy` or `ubuntu` user. One SSH key, everyone uses it. Fast to set up, impossible to audit. When something breaks in production - or something gets deleted - you have no idea who was logged in. The logs say `ubuntu`. That's where the investigation ends.
---
## The drift nobody notices
The manual approach creates drift quietly. Keys that should have been removed are still there. A contractor who left six months ago can still log in. Nobody knows exactly who has access to what because it lives scattered across the configuration of individual servers, not in any one place you can actually look at.
You only find out how bad it is during a breach, an audit, or a compliance review.
---
## Where the idea came from
I worked at Yahoo from 2005 to 2007. One of the internal tools we used was yinst - a package manager built for Yahoo's massive server fleet. Among other things, it handled adding and removing users across servers. One command, right setup, clean removal.
I didn't think much of it at the time. That was just how things worked at Yahoo.
Years later, building and managing infrastructure at smaller companies, I kept noticing the absence of it. The manual approach isn't wrong exactly - it works fine when the team is small and careful. But it doesn't scale with the team, and it has no memory. When someone leaves or an audit arrives, you're reconstructing history from Slack messages and gut feel.
addy is my attempt to bring that same idea - one command, predictable outcome, Git as the record - to teams that don't have a hundred infra engineers to build it from scratch.
---
## What addy does
addy treats server access like a package. Your team's SSH public keys live in a Git repository. addy reads from that repository and applies changes to your server.
```
sudo addy install user/alice # creates Linux user, installs SSH key
sudo addy install sudo/alice # grants passwordless sudo
sudo addy remove sudo/alice # revokes sudo
sudo addy remove user/alice # removes access entirely
```
No database. No service to run. No web interface to maintain. Just a Git repo and simple commands.
When someone joins, you add their public key to the repo and run one command. When they leave, you remove the key and run one command. Their access is gone - cleanly, completely, verifiably. No shared users. No drift.
---
## Why Git is the right place for this
Git gives you two things that matter here.
The first is workflow. Instead of sharing public keys over Slack and hoping someone copies them correctly, engineers open a pull request to add their key to the repository. The team can review it, the change is visible, and there's a clear record of when it was merged.
The second is audit trail. Every key addition and removal is a commit. When a compliance team asks "show me every access change in the last six months," you have an answer - not a pile of Slack threads to go through.
The actual granting of access - creating the user on the server, installing the key, updating permissions - still happens through addy commands. That part isn't automatic. But because the keys live in Git, the record of who should have access is always in one place, versioned, and reviewable.
---
## The setup
```
pip install addy
sudo addy config set git-repo git@github.com:your-org/ssh-keys.git
sudo addy install user/alice
```
Your key repository needs one thing: a `users/` directory with `.pub` files named after each person.
```
users/
alice.pub
bob.pub
charlie.pub
```
addy handles creating the Linux user, installing the key to the right location, setting correct file permissions, and validating the key format before doing any of it. For sudo access, it writes a sudoers file and validates it with `visudo` - so a malformed entry doesn't accidentally lock you out.
---
## Who this is for
Teams of 5 to 50 people. Big enough to have real access management overhead. Small enough that nobody has built internal tooling for it yet.
If you're managing server access through Slack messages and shared users, addy is worth an hour of your time.
The alternative is finding out - during an audit or after an incident - that you don't actually know who has access to what, and no log to help you figure it out.
[github.com/abhinavs/addy](https://github.com/abhinavs/addy)
---
# Microservices are a people decision, not a technical one.
URL: https://www.abhinav.co/microservices-a-way-to-organize-teams
Date: 2026-02-21T00:00:00+00:00
I've seen companies running thirty microservices with a twelve-person engineering team.
Nobody questions it. Microservices have become the default answer to "how should we structure our system?" - adopted for the wrong reasons, creating new problems while the old ones quietly follow along.
My unpopular opinion - microservices are mostly a way to organise teams, not to scale systems. And most companies that adopt them are doing it backwards.
---
## The actual value
Mel Conway observed in 1967 that organisations design systems that mirror their own communication structure. Three teams building together produce a three-part system - whether that's the right architecture or not.
This is the real case for microservices. When the payments team owns the payments service end to end - builds it, deploys it, fixes it at 2am - they stop waiting on five other teams to ship a change. Reduced coordination. Clearer ownership. That's worth something.
But it only works when the split is real. One team, one thing, completely.
Most companies don't do it this way.
---
## The mistake
The most common thing I've seen: splitting code without splitting ownership.
You have a user service, an auth service, an account service. They all touch the same user data. Any change to how a user is represented requires coordinating across three teams. The services are separate. The work isn't.
The mess hasn't gone away. It's moved into the gaps between services.
And when something breaks, it breaks across multiple services at once. A bug that takes an hour to find in a monolith takes a day when you're tracing requests through four systems and reading logs from three different places.
Every service also needs its own deployment pipeline, its own monitoring, its own on-call rotation. At Netflix this overhead is justified. At a 20-person startup it's a tax on every engineer, every day. I've watched teams ship at half their previous speed after going microservices - not because the technology was wrong, but because the team wasn't big enough to carry the weight.
---
## Why this matters more now
AI coding agents change the calculation further.
An agent can hold an entire codebase in context and make changes across multiple modules without getting lost. What's harder is reasoning across service boundaries - different repositories, different API contracts, different deployment pipelines. Every boundary you add is friction for the agent.
A modular monolith, where code is well-structured but lives in one place, is significantly easier for an agent to work with. I think this is where most teams will land as AI-assisted development matures - not because microservices are wrong, but because the tool that's transforming how we build software works best with fewer walls.
---
## When to actually use them
Microservices make sense when teams are genuinely separate - different product lines, different shipping cadences, minimal coordination needed. They make sense when one part of your system has dramatically different scaling needs from the rest. At real scale, the operational overhead is worth it.
The mistake is using them as the starting point. Start with a well-structured monolith. Split when you have a specific reason to split, not because microservices sound like the professional choice.
The architecture should follow the team structure. Most of the time, the team is smaller than the architecture suggests.
---
# On learning new things without old baggage
URL: https://www.abhinav.co/learning-new-things-without-baggage
Date: 2026-02-27T00:00:00+00:00
Whenever I'm in Bangalore, I still default to Hindi.
I lived there for ~6 years, but I never really learned Kannada. The moment someone spoke to me, my brain looked for a Hindi equivalent and came up short.
Kids don't do this. A child learning a new language maps words to real things - the sound and the reality arrive together.
Adults, on the other hand, map words to other words. Duolingo does this too - every lesson maps the new language onto the one you already know. No wonder so few learners ever hold a real conversation.
The same pattern shows up when engineers learn new programming paradigms.
I learned C first. Then tried jumping to Java. Object-oriented programming felt alien - I kept asking "what's the C equivalent of this?" and half the time, there wasn't one. I gave up, took a detour through Perl, and arrived at objects gradually. The direct path didn't work because I was carrying the old map into new territory.
This is exactly what's happening with AI right now.
Most people learn AI tools by mapping them onto familiar things. ChatGPT is like Google, but better. Copilot is like autocomplete, but smarter. An agent is like a junior employee you can delegate to.
These analogies help you start. They also limit how far you go.
I'll be honest - I catch myself doing this too. Twenty years in tech means twenty years of mental models that I keep reaching for, even when they don't quite fit.
The people I've seen get the most out of AI are often the ones without that baggage. AI-native - they didn't learn to Google before ChatGPT, didn't debug by posting on Stack Overflow before Claude Code. They're not translating. They're just using it for what it is.
That model doesn't come from reading about AI. It comes from approaching it with fresh eyes, not a map drawn from somewhere else.
The ceiling isn't the tool. It's the map you bring to it. And I'm still drawing a new one.
---
# AI doesn't have a Moore's Law
URL: https://www.abhinav.co/ai-curves
Date: 2026-04-21T00:00:00+00:00
## It has something harder to name, and harder to ignore.
In January 2023, two months after ChatGPT launched, I started building [annexr](https://annexr.com). I thought I was late. Three years later, I realize I was early.
That mismatch - feeling late while being early - is the signature experience of building in AI right now. It has nothing to do with individual foresight. It has everything to do with how progress in this field compounds.
---
## One curve vs. many
Moore's Law was one curve: transistor density doubling on a predictable clock. Clean, measurable, predictive. And even that wasn't a natural law. At Intel, it was a goal the company worked hard to keep. When physics pushed back, they adapted.
AI progress isn't like that. There is no single company shepherding a single metric. It is a bundle of partially correlated curves: compute, algorithms, inference cost, hardware efficiency, and how long AI systems can work without a human in the loop.
What makes this unusual is that two different kinds of improvement run at once.
- [Moore's Law](https://en.wikipedia.org/wiki/Moore%27s_law) runs on the calendar. Time passes, chips improve.
- [Wright's Law](https://en.wikipedia.org/wiki/Experience_curve_effects) runs on cumulative work done. The more you make something, the cheaper it gets.
In AI, both are active simultaneously. That coupling is what makes progress feel relentless. The decoupling is what produces the walls.
---
## The curves, briefly
Four numbers worth knowing:
- **Training compute** has grown roughly 4.5x per year since 2010
- **Algorithmic efficiency** improves separately: the same capability now takes about 3x less compute each year
- **Inference cost** has fallen by orders of magnitude, anywhere from 9x to 900x per year depending on the task
- **Agent task horizon** - how long an AI can work before needing help - has been doubling roughly every four months
These aren't independent. Falling inference cost enables more compute at inference time, which improves reasoning, which pushes the task-horizon curve further, until it hits a wall.
---
## Where the curves break
**The logarithmic trap.** Benchmark performance scales roughly with the log of compute. Each doubling of performance costs far more than a doubling of the training budget. The current bet is test-time compute, shifting spend from training to reasoning during use. Whether the economics hold at scale is still open.
**The data wall.** High-quality human text is largely exhausted at frontier training scales. Synthetic data and model self-play have kept the curve alive in narrow domains like math and code. Whether they generalize is the open question.
**The reliability gap.** Task horizon measures length, not robustness. An agent that can work for a hundred hours but has a 1% chance of failure each hour is unusable for anything high-stakes. Reliability data lags capability data badly, which is itself a signal about what the industry has optimized for.
**The power grid.** Moore's Law was about density, doing more in the same space. AI scaling is about absolute magnitude. Bigger clusters need more gigawatts. Power grids follow civil engineering timelines, not silicon ones.
**The institutional curve, which is essentially flat.** Compliance, procurement, security review, change management: none of these scale exponentially. The AI curves are steep. The institutional curve is close to flat.
---
## What this means practically
The line of what is worth building keeps moving. Something too expensive or too unreliable last quarter can make sense this quarter. Something that barely works today can be boring infrastructure a year from now.
But the problems blocking real adoption have shifted. They are no longer mostly about capability. They are about reliability, power capacity, data quality, and how long it takes large organizations to trust new systems.
Most of the interesting work for the rest of this decade sits in closing the gap between a steep capability curve and a nearly flat institutional one. Not pushing the frontier further. Getting organizations to the threshold.
That is a harder problem than making the models smarter. It is also a more tractable one.
---
*If you want the backstory on how these three threads came together, I wrote about that separately: [The AI moment was seventy years in the making](/ai-three-lines).*
---
## Sources and further reading
- [Moore's Law](https://en.wikipedia.org/wiki/Moore%27s_law)
- [Wright's Law / Experience curve effects](https://en.wikipedia.org/wiki/Experience_curve_effects)
- [Epoch AI: Trends in frontier AI training compute and algorithmic efficiency](https://epoch.ai/trends)
- [Epoch AI: LLM inference price trends](https://epoch.ai/data-insights/llm-inference-price-trends)
- [METR: Measuring AI ability to complete long tasks (Jan 2026 update)](https://metr.org/blog/2026-1-29-time-horizon-1-1/)
- [Stanford HAI: AI Index Report](https://hai.stanford.edu/ai-index/2025-ai-index-report)
---
# The AI moment was seventy years in the making
URL: https://www.abhinav.co/ai-three-lines
Date: 2026-04-21T00:00:00+00:00
_Three independent lines of work. Each took decades. None waited for the others._
---
In 1947, Bell Labs invented the transistor. A year later, Claude Shannon, working in the same building, published a paper on the mathematics of communication. Neither discovery knew what it was starting.
What we call "the AI moment" is not one thing. It is the convergence of three threads, each of which matured on its own schedule, developed independently of the others.
---
## The first thread: a language for information itself
In 1948, [Claude Shannon](https://en.wikipedia.org/wiki/Claude_Shannon) published [_A Mathematical Theory of Communication_](https://en.wikipedia.org/wiki/A_Mathematical_Theory_of_Communication). He was trying to solve a practical problem: how do you transmit a signal reliably over a noisy channel?
What he produced was something much larger. A mathematical language for information itself. Entropy. Compression. Channel capacity. The idea that meaning could be separated from medium, quantified, and reasoned about formally.
It laid the mathematical foundation that machine learning, deep learning, and modern AI are built on. Every token prediction in a modern language model is a descendant of that paper. Shannon did not know he was laying the foundation for AI. He was solving a telephone problem.
---
## The second thread: hardware that could actually run the math
The [transistor](https://en.wikipedia.org/wiki/Transistor) was invented in 1947. Seven decades of shrinking, specializing, and parallelizing followed.
The moment hardware met modern AI visibly was 2012. A team at the University of Toronto trained a neural network called [AlexNet](https://en.wikipedia.org/wiki/AlexNet) on GPUs and won [ImageNet](https://en.wikipedia.org/wiki/ImageNet) by a margin that made everyone in the field stop and recalculate. GPUs were designed for graphics. They turned out to be the right shape for deep learning: massively parallel, fast at matrix operations, cheap enough to experiment with.
Google followed with custom silicon. TPUs arrived in 2016, designed specifically for neural network workloads. The physical substrate that made scale possible was now being purpose-built for it.
---
## The third thread: an architecture that changed everything
In June 2017, a team at Google published [_Attention Is All You Need_](https://arxiv.org/abs/1706.03762). The paper proposed the [Transformer](): a new architecture that dropped recurrence entirely and used attention mechanisms to process sequences in parallel.
Google understood it well enough to ship BERT in 2018 and T5 in 2019. What it did not do was productize at the pace the architecture deserved. The constraint was probably search revenue. If your core business is people finding answers on web pages, a model that answers questions directly is a threat you have to manage carefully.
OpenAI had no such constraint. GPT-2 in 2019. GPT-3 in 2020. The technical trajectory was visible to anyone watching. The three threads had already crossed.
---
## What actually happened in 2022
By the time ChatGPT launched in November 2022, nothing fundamental had changed in the underlying technology. The models were better, but the architecture, the hardware, the training approach: all of it had been in place for years.
What changed was the interface. A chat box that anyone could use. No API key. No prompting knowledge required. The intersection of seventy years of work was suddenly in front of everyone with an internet connection.
The rupture of 2022 was not a moment of invention. It was a moment of attention.
---
The three threads took different amounts of time. Shannon's 1948 paper needed sixty years of hardware before it could run at scale. The Transformer needed less than five years to go from research paper to the technology inside a product used by a hundred million people.
The gap between discovery and deployment has been shrinking the whole time. That, more than any single breakthrough, is what makes the current moment feel different from the ones before it.
---
_The follow-on question, where those curves are headed and where they break, is what I wrote about in [AI doesn't have a Moore's Law](/ai-curves)._
---
# Terminal is having a second life
URL: https://www.abhinav.co/terminal-is-having-a-second-life
Date: 2026-04-22T00:00:00+00:00
In 2001 I started with telnet.
I was a student at [BITS Pilani](https://www.bits-pilani.ac.in/) and [telnet](https://en.wikipedia.org/wiki/Telnet) was simply how you got to the internet. I used [Pine](https://en.wikipedia.org/wiki/Pine_(email_client)) to send email. [Lynx](https://en.wikipedia.org/wiki/Lynx_(web_browser)) to browse. The world came to me as text on a black screen and I thought nothing of it. It was just how computers worked.
Then GUIs got faster, browsers got richer, and the terminal slowly became the thing you minimised and forgot about. Developers kept using it. Everyone else moved on.
I kept using it too. At Yahoo in 2005, the terminal was where the real work happened. I was working on a big data processing pipeline and my QA system was a pipe. Feed the output through `grep`, filter it with `cut`, join datasets with `join`, scan compressed logs with `zcat` and `zgrep`. Each tool did one thing. The intelligence lived in how you chained them. And if something went wrong, the tool that failed said so. The pipeline stopped. You knew exactly where to look.
It felt powerful then. I didn't fully understand why.
---
I've spent the last two months building [vrk](https://vrk.sh) -- Unix-style tools for LLM pipelines -- and the Yahoo pipeline keeps coming back to me.
Not as nostalgia. As explanation.
AI agents need to do things: fetch a URL, check it fits within a model's token limit, redact secrets, call the model, validate the output. The problem is what happens when something goes wrong. A model doesn't crash on bad input. It guesses. It fills in what it didn't see with text that sounds right. You find out three steps later, or you don't find out at all.
Agents, like the shell, are probabilistic at the edges but need determinism at the joints. The pipes are the joints.
That's the insight I kept arriving at while building vrk. The contract that made `grep` useful -- stdin in, stdout out, exit loudly on failure -- turns out to be exactly the contract an agent pipeline needs.
---
I started using the terminal because it was all there was. I keep using it because nothing that came after improved on the pipe.
---
# Introducing Soniq
URL: https://www.abhinav.co/soniq
Date: 2026-05-03T00:00:00+00:00
## Soniq - the job queue for people who don't want another job queue
I've been rebuilding the same job scheduler since 2011.
The first version used MongoDB. The core trick was `find_and_modify` -- MongoDB's atomic operation that lets you fetch a document and update it in a single step. Claim a job before anyone else does, or don't claim it at all. No double processing. I ran a [hosted multi-tenant version](https://github.com/abhinavs/scheduler_service) for two or three years. People used it. It mostly worked.
Then I moved on. But the problem stayed with me.
---
Over the years I've used most of the serious job queue libraries. Resque and Sidekiq in Ruby. RQ in Python. Each one solved the core problem well enough. Each one also required something extra: Redis, a specific runtime, or an entirely different programming model. The closest thing to what I wanted was Oban in Elixir -- PostgreSQL-backed, no broker, no Redis. But I was building in Python.
I kept thinking about the infra cost. Not the money, but the maintenance. Every component you add to a production system is something that can fail, something you have to monitor, something you have to explain to whoever reads your deploy config next. Redis is not expensive to run. But Redis is one more thing to run.
I believe in [boring infrastructure](https://mcfunley.com/choose-boring-technology). The best infra component is usually the one you don't add. Most Python applications already run PostgreSQL. Your jobs can too. It's already there. It's already backed up. You already understand it.
---
Last year I built Fastjob. PostgreSQL as the datastore, transactional enqueue, dashboard, webhooks, scheduler. Feature-rich. I'm also willing to admit it became complicated. I added things before the core was solid, and eventually the project became what I was trying to avoid: one more thing to manage.
In January this year I started again, on weekends. I call it Soniq.
---
Soniq is a batteries-included async job queue for Python. The only infrastructure dependency is PostgreSQL.
No Redis cluster. No separate broker. No operational split brain between your app state and your queue state.
If your application already depends on PostgreSQL, your queue can too.
What that gives you that most queues don't:
- Transactional enqueue. A job is either committed or it isn't. A user signs up, the database transaction commits, the welcome email job commits in the same transaction - there is no gap where one succeeds and the other disappears.
- Built-in scheduler and recurring jobs
- Built-in dashboard, no paid tier
- Prometheus metrics out of the box
Most applications don't need a dedicated distributed queue cluster just to send emails and process background tasks. Soniq is built for that majority - teams that need reliability and operational simplicity more than extreme throughput.
If you're already running PostgreSQL and don't want another broker, [Soniq is ready](https://github.com/abhinavs/soniq) - MIT licensed, batteries included.
---
# Introducing sqlalchemy-annotate
URL: https://www.abhinav.co/sqlalchemy-annotate
Date: 2026-05-19T00:00:00+00:00
I have released `sqlalchemy-annotate`, a small command-line tool that keeps a schema summary at the top of every SQLAlchemy model file.
When you read a SQLAlchemy model, the Python tells you which attributes exist but not what the database does with them. Whether a column is nullable, how long a string can be, which columns are indexed, what the foreign keys point at - none of that is visible in the model. You have to open the migration or connect to the database to find out. Rails has addressed this for years with `annotate_models`. This tool brings the same idea to modern SQLAlchemy 2.x and Alembic projects.
It maintains a block like this, kept in sync with your actual metadata:
```
# == Schema Information
#
# Table name: users
#
# id : integer, primary key
# email : varchar, not null
# created_at : timestamp
#
# Indexes
# ix_users_email (email) UNIQUE
#
# == End Schema Information
```
There are three commands. `sqlalchemy-annotate generate` writes or updates the block, typically run after a migration. `sqlalchemy-annotate check` exits non-zero when a model has drifted from its comment, which makes it suitable as a CI gate or pre-commit hook. `sqlalchemy-annotate remove` strips every block.
Two design decisions are worth stating directly.
First, it never connects to a database. The schema is read from `Base.metadata`. If you pass a connection URL, only its dialect is used, so types compile correctly offline, and the URL is then discarded. Annotating a file does not require database credentials.
Second, it does not rewrite files with regular expressions. All edits go through a single libcst transformer, so imports, comments, blank lines and formatting outside the marked block are preserved exactly. Running `generate` twice produces no further change, which is what makes `check` reliable.
One trade-off should be clear before you adopt it. The tool imports your model package, in the same way pytest and Alembic do. If importing your models triggers side effects, those will run. For most projects this is not an issue, but it is worth knowing.
Installation is from PyPI:
```
pip install sqlalchemy-annotate
```
The source, full documentation and configuration options are at [github.com/abhinavs/sqlalchemy-annotate](https://github.com/abhinavs/sqlalchemy-annotate). The tool is intentionally small. The schema already exists in your metadata; this simply puts it where the person reading the model can see it.
Scoop uses
1. [Corneal](http://thebrianemory.github.io/corneal/) to make scaffolding models, controllers and views easier
2. ActiveRecord as database ORM
3. Capistrano for deployment
4. Puma as app server
5. Nginx as a proxy server
In addition,
1. it is also JSON API ready with JSON, CORS and JSONP support already enabled,
2. has a rails like console, and
3. comes up with example script and rake task that can be used to perform tasks that load the environment
You can start using Scoop by [forking this repository](https://github.com/abhinavs/scoop/fork). Scoop's [README](https://github.com/abhinavs/scoop/blob/master/README.md) has detailed steps to set up development and production systems as well as the deployment process.
Do give Sinatra & Scoop a try.
---
# Web3 - new yet old
URL: https://www.abhinav.co/web3-and-the-chasm
Date: 2021-11-07T00:00:00+00:00
Consider these questions:
- How did stock exchanges around the world originate?
- Why do governments allow them to function when they resemble gambling?
- What steps do governments take to keep them relatively safer options for investors?
I think the history of stock markets and these questions are tied to the new web3/crypto/DeFi and its future. After all, promises of shares and tokens are almost the same - communal ownership.[^1]
[Dutch East India Company](https://en.wikipedia.org/wiki/Dutch_East_India_Company) was a special company. It was the first company to issue shares to the general public. Company had a big mission and required a lot of investment. At the same time, the possibility of lucrative dividends was high. As a result, the company's and its investors' incentives were aligned.
This was the start of public companies. Quite soon people started trading their shares in the companies. Again incentives were aligned - folks with shares could get liquid money whereas the new shareholders could earn from dividends. Gradually, people were making more money by trading shares than from dividends. They would buy shares at a lower price and sell it to others at a higher price.
People started forming narratives about the companies, they also started studying financial data better to supplement the narrative. However, as it happens in the world, a lot of fraud mechanisms also emerged.[^2]
Now, many of these companies were really **important for the economy**. Some were developing modern infrastructure and hence governments started creating regulations to protect both companies and investors from these frauds. Today, while fraud has not gone completely to zero, stock exchanges are relatively safer and well-regulated.
If you see, a lot of web3 promises seem to be exactly the same as companies of earlier generations promised via shares.
However, there is very little regulation - well, that's intentional, after all decentralization is a key foundational pillar and any form of government regulation will be seen as the defeat of the original goal.
However, there's a big [chasm](https://en.wikipedia.org/wiki/Crossing_the_Chasm) that web3 still needs to cross[^3].
{:class="img-responsive"}
From this perspective I see following four distinct scenarios playing out:
1. Status Quo - web3 continues to operate without any regulation. Community self organizes and ensures that its true promise is fulfilled.
2. Governments get involved - the progressive ones try regulating it accordingly, and a few others ban them. Gradually, it gets to the balance that helps it grow, but with a few compromises.
3. Big VC firms, large companies, early believers and lobbyists keep pushing the narrative and pump in users and money. It becomes too big to fail and crosses the chasm. Governments don't regulate it at all because of various reasons (including political ones)
4. Bubble bursts. Everybody except true believers leaves. Chaos settles a bit, and these believers then create infra and use cases that help web3 cross the chasm.
Future is unpredictable. Narratives are linear and have survivor bias. What happens in the world is chaotic and non-linear. Even in web3, pragmatically speaking, a bit of everything will happen.
I do think that web3 tech, while still in its infancy, is quite neat. However, it has a long way to go. I just hope greed, fraud and associated chaos doesn't hinder web3 from reaching its full potential.
## Footnotes
[^1]: To be honest, tokens are in a lot of ways better because they are Internet native, are programmable with smart contracts and a lot more capabilities.
[^2]: A few simple fraud mechanisms were stealing share certificates, exaggerated narratives, pump and dump etc. Surprisingly many of them, in some form, exist in the web3 world too.
[^3]: Web3 critics say that cryptocurrencies haven't solved any solid use cases even after a decade of existence. Web3 believers however feel that it is still in the infrastructure creation stage, and interesting use cases will be built when the right infra is in place.
---
# Designing Microservices
URL: https://www.abhinav.co/designing-microservices
Date: 2022-08-07T00:00:00+00:00
I was recently asked about considerations while migrating to microservices architecture. While I believe not every company needs microservices, they can be really useful in scaling your org and systems.
Here are some of the top things I would keep in mind:
1. **Abstraction** - how well a problem is abstracted so that it doesn’t leak its core business rules to other services, at the same time does only one or two things.
2. **Independent DB(s)** - doesn’t share its database with other microservices. One micro-service, however, definitely can use multiple databases.
3. **Latency and number of microservices that hit in a flow** - this should ideally be limited to a specific number. P95, P99 latency, and error rates should be tracked and monitored.
4. **DAG** - there’s no circular dependency, and the relationship between microservices is ‘Directed Acyclic Graph’. This will keep dependencies, latencies, and complexity in check.
5. **Classification between core and auxiliary services** - the idea is if any of the auxiliary services die, users should face a degraded experience but no downtime.
6. **SDK** - build SDK that microservices can use to call other microservices. The idea is that this SDK becomes a core library with its inbuilt logic around logging metrics and handling degraded behavior (constructs like circuit breakers)
7. **Platform Services & Modules** - in addition, a lot of duplicated code across microservices should be pulled out and abstracted either as a supporting service or library (ex. locking, scheduler - no business logic though, connection pooling, throttling, analytics logger)
8. **Team** - take into consideration how your org structure would evolve in the next 2-3 years, the kind of product and platform teams you would have, and ensure no microservice is shared between teams.
---
# Data science libraries in Python and Elixir
URL: https://www.abhinav.co/data-science-python-vs-elixir
Date: 2022-10-04T00:00:00+00:00
Data science in Elixir is maturing at a rapid pace. This post lists data science libraries in Python along with their Elixir equivalent.
### Notebooks
- Python: Jupyter
- Elixir: [Livebook](https://livebook.dev)
### Numerical Analysis
- Python: NumPy
- Elixir: [Nx](https://hexdocs.pm/nx/Nx.html)
### Traditional Machine Learning
- Python: scikit-learn
- Elixir: [Scholar](https://github.com/elixir-nx/scholar)
### Deep learning
- Python: PyTorch / TensorFlow
- Elixir: [Axon](https://hexdocs.pm/axon/Axon.html)
It is also possible to use pre-trained models, you can use [AxonOnnx](https://hexdocs.pm/axon_onnx/AxonOnnx.html) for it.
### Data analysis
- Python: Pandas
- Elixir: [Explorer](https://hexdocs.pm/explorer/Explorer.html)
Explorer is built on top of polars library which is a lightning fast DataFrames implementation in Rust.
### Data presentation and visualization
- Python: Plotly Express / matplotlib
- Elixir: [VegaLite](https://hexdocs.pm/vega_lite/VegaLite.html)
VegaLite is Elixir bindings to Vega-Lite, a high-level grammar of interactive graphics.
### Network and geographic visualization
- Python: NetworkX (network), Folium (geo)
- Elixir: no equivalent so far
### Pipelines and orchestration
- Python: tf data, DataLoader
- Elixir: [Broadway](https://hexdocs.pm/broadway/introduction.html) and [Flow](https://hexdocs.pm/flow/Flow.html)
Elixir runs over Erlang VM called BEAM, and hence by design can work better than Python processing data in concurrent and fault-tolerant manner.
### Domain specific
For custom domains like NLP, computer vision and signal processing, Elixir libraries are still being worked upon.
---
# Notes on CBDC
URL: https://www.abhinav.co/notes-on-cbdc
Date: 2022-10-09T00:00:00+00:00
RBI has recently published a concept note on Central Bank's Digital Currency (CBDC) - it is available to read [here](https://rbidocs.rbi.org.in/rdocs/PublicationReport/Pdfs/CONCEPTNOTEACB531172E0B4DFC9A6E506C2C24FFB6.PDF).
I glanced through it and found it pretty interesting. At a personal level, I'm quite hopeful that a well-implemented CBDC can marry the benefits of cash with current pseudo-digital money.
### Why CBDC
At the moment ~3% of GDP is spent on printing, distributing, and securely storing cash. Moreover, India has around 15-30% of its GDP as a shadow economy (not all of the shadow economy is illegal, but much of it is)
Digital money in its current form (credit card, UPI) has too many entities in the middle to solve for trust. As a result, these entities charge ~2% of the transaction cost from the merchant (which essentially gets passed to customers)
I also believe, a well-implemented CBDC also has a shot to replace USD as the reserve currency of the world. China has already made some progress in implementing digital Yuan (eCNY) - AFAIK, it is primarily targeting transactions between banks (rightfully so)
China's progress is one of the key reasons why India and RBI are also so keen on CBDC
### CBDC & its implementation
Introducing CBDC should not mean that banks lose their relevance, however, it should mean they do high-order things more efficiently. As an example, they should still be the ones doing KYC, however, their recon & settlement process should be way more efficient because of CBDC.
RBI's concept note on CBDC distinguishes between retail (CBDC-R) and inter-banking entities (CBDC-W) and their respective implementation details.
I think,
- CBDC can be implemented without using blockchain and yet can be distributed with no single point of failure (think about how SSL/HTTPS certificates work)
- Direct benefit transfer (DBT) scheme launched by the govt could be more efficient with smart CBDC
**TODO: update with the design I think can work without blockchain**
### Further Reading
1. [Deepening of Digital Payments Report](https://rbidocs.rbi.org.in/rdocs//PublicationReport/Pdfs/CDDP03062019634B0EEF3F7144C3B65360B280E420AC.PDF) (January 2019) - it was written by a committee that worked under the chairmanship of Mr Nandan Nilekani.
2. [Central Bank Digital Currency – Is This the Future of Money](https://youtu.be/xoXA_mVJ504) - another interesting speech by Mr. Rabi Sankar, Deputy Governor, RBI. He talks about the difference between currency & money, then presents RBI's viewpoint. [Transcript](https://www.rbi.org.in/Scripts/BS_SpeechesView.aspx?Id=1111)
---
# addy - like apt install, but for people
URL: https://www.abhinav.co/addy
Date: 2025-07-21T00:00:00+00:00
Every company has a version of this problem.
A new engineer joins. Someone sends a Slack message to whoever manages the servers. That person sets up access when they find the time - creating accounts, copying keys, updating permission files. All done by hand, all from memory. When that engineer leaves, most of this gets undone. Some of it doesn't - old access quietly lingers on servers nobody thinks to check.
Some teams give up and share a common `deploy` or `ubuntu` user. One SSH key, everyone uses it. Fast to set up, impossible to audit. When something breaks in production - or something gets deleted - you have no idea who was logged in. The logs say `ubuntu`. That's where the investigation ends.
---
## The drift nobody notices
The manual approach creates drift quietly. Keys that should have been removed are still there. A contractor who left six months ago can still log in. Nobody knows exactly who has access to what because it lives scattered across the configuration of individual servers, not in any one place you can actually look at.
You only find out how bad it is during a breach, an audit, or a compliance review.
---
## Where the idea came from
I worked at Yahoo from 2005 to 2007. One of the internal tools we used was yinst - a package manager built for Yahoo's massive server fleet. Among other things, it handled adding and removing users across servers. One command, right setup, clean removal.
I didn't think much of it at the time. That was just how things worked at Yahoo.
Years later, building and managing infrastructure at smaller companies, I kept noticing the absence of it. The manual approach isn't wrong exactly - it works fine when the team is small and careful. But it doesn't scale with the team, and it has no memory. When someone leaves or an audit arrives, you're reconstructing history from Slack messages and gut feel.
addy is my attempt to bring that same idea - one command, predictable outcome, Git as the record - to teams that don't have a hundred infra engineers to build it from scratch.
---
## What addy does
addy treats server access like a package. Your team's SSH public keys live in a Git repository. addy reads from that repository and applies changes to your server.
```
sudo addy install user/alice # creates Linux user, installs SSH key
sudo addy install sudo/alice # grants passwordless sudo
sudo addy remove sudo/alice # revokes sudo
sudo addy remove user/alice # removes access entirely
```
No database. No service to run. No web interface to maintain. Just a Git repo and simple commands.
When someone joins, you add their public key to the repo and run one command. When they leave, you remove the key and run one command. Their access is gone - cleanly, completely, verifiably. No shared users. No drift.
---
## Why Git is the right place for this
Git gives you two things that matter here.
The first is workflow. Instead of sharing public keys over Slack and hoping someone copies them correctly, engineers open a pull request to add their key to the repository. The team can review it, the change is visible, and there's a clear record of when it was merged.
The second is audit trail. Every key addition and removal is a commit. When a compliance team asks "show me every access change in the last six months," you have an answer - not a pile of Slack threads to go through.
The actual granting of access - creating the user on the server, installing the key, updating permissions - still happens through addy commands. That part isn't automatic. But because the keys live in Git, the record of who should have access is always in one place, versioned, and reviewable.
---
## The setup
```
pip install addy
sudo addy config set git-repo git@github.com:your-org/ssh-keys.git
sudo addy install user/alice
```
Your key repository needs one thing: a `users/` directory with `.pub` files named after each person.
```
users/
alice.pub
bob.pub
charlie.pub
```
addy handles creating the Linux user, installing the key to the right location, setting correct file permissions, and validating the key format before doing any of it. For sudo access, it writes a sudoers file and validates it with `visudo` - so a malformed entry doesn't accidentally lock you out.
---
## Who this is for
Teams of 5 to 50 people. Big enough to have real access management overhead. Small enough that nobody has built internal tooling for it yet.
If you're managing server access through Slack messages and shared users, addy is worth an hour of your time.
The alternative is finding out - during an audit or after an incident - that you don't actually know who has access to what, and no log to help you figure it out.
[github.com/abhinavs/addy](https://github.com/abhinavs/addy)
---
# Microservices are a people decision, not a technical one.
URL: https://www.abhinav.co/microservices-a-way-to-organize-teams
Date: 2026-02-21T00:00:00+00:00
I've seen companies running thirty microservices with a twelve-person engineering team.
Nobody questions it. Microservices have become the default answer to "how should we structure our system?" - adopted for the wrong reasons, creating new problems while the old ones quietly follow along.
My unpopular opinion - microservices are mostly a way to organise teams, not to scale systems. And most companies that adopt them are doing it backwards.
---
## The actual value
Mel Conway observed in 1967 that organisations design systems that mirror their own communication structure. Three teams building together produce a three-part system - whether that's the right architecture or not.
This is the real case for microservices. When the payments team owns the payments service end to end - builds it, deploys it, fixes it at 2am - they stop waiting on five other teams to ship a change. Reduced coordination. Clearer ownership. That's worth something.
But it only works when the split is real. One team, one thing, completely.
Most companies don't do it this way.
---
## The mistake
The most common thing I've seen: splitting code without splitting ownership.
You have a user service, an auth service, an account service. They all touch the same user data. Any change to how a user is represented requires coordinating across three teams. The services are separate. The work isn't.
The mess hasn't gone away. It's moved into the gaps between services.
And when something breaks, it breaks across multiple services at once. A bug that takes an hour to find in a monolith takes a day when you're tracing requests through four systems and reading logs from three different places.
Every service also needs its own deployment pipeline, its own monitoring, its own on-call rotation. At Netflix this overhead is justified. At a 20-person startup it's a tax on every engineer, every day. I've watched teams ship at half their previous speed after going microservices - not because the technology was wrong, but because the team wasn't big enough to carry the weight.
---
## Why this matters more now
AI coding agents change the calculation further.
An agent can hold an entire codebase in context and make changes across multiple modules without getting lost. What's harder is reasoning across service boundaries - different repositories, different API contracts, different deployment pipelines. Every boundary you add is friction for the agent.
A modular monolith, where code is well-structured but lives in one place, is significantly easier for an agent to work with. I think this is where most teams will land as AI-assisted development matures - not because microservices are wrong, but because the tool that's transforming how we build software works best with fewer walls.
---
## When to actually use them
Microservices make sense when teams are genuinely separate - different product lines, different shipping cadences, minimal coordination needed. They make sense when one part of your system has dramatically different scaling needs from the rest. At real scale, the operational overhead is worth it.
The mistake is using them as the starting point. Start with a well-structured monolith. Split when you have a specific reason to split, not because microservices sound like the professional choice.
The architecture should follow the team structure. Most of the time, the team is smaller than the architecture suggests.
---
# On learning new things without old baggage
URL: https://www.abhinav.co/learning-new-things-without-baggage
Date: 2026-02-27T00:00:00+00:00
Whenever I'm in Bangalore, I still default to Hindi.
I lived there for ~6 years, but I never really learned Kannada. The moment someone spoke to me, my brain looked for a Hindi equivalent and came up short.
Kids don't do this. A child learning a new language maps words to real things - the sound and the reality arrive together.
Adults, on the other hand, map words to other words. Duolingo does this too - every lesson maps the new language onto the one you already know. No wonder so few learners ever hold a real conversation.
The same pattern shows up when engineers learn new programming paradigms.
I learned C first. Then tried jumping to Java. Object-oriented programming felt alien - I kept asking "what's the C equivalent of this?" and half the time, there wasn't one. I gave up, took a detour through Perl, and arrived at objects gradually. The direct path didn't work because I was carrying the old map into new territory.
This is exactly what's happening with AI right now.
Most people learn AI tools by mapping them onto familiar things. ChatGPT is like Google, but better. Copilot is like autocomplete, but smarter. An agent is like a junior employee you can delegate to.
These analogies help you start. They also limit how far you go.
I'll be honest - I catch myself doing this too. Twenty years in tech means twenty years of mental models that I keep reaching for, even when they don't quite fit.
The people I've seen get the most out of AI are often the ones without that baggage. AI-native - they didn't learn to Google before ChatGPT, didn't debug by posting on Stack Overflow before Claude Code. They're not translating. They're just using it for what it is.
That model doesn't come from reading about AI. It comes from approaching it with fresh eyes, not a map drawn from somewhere else.
The ceiling isn't the tool. It's the map you bring to it. And I'm still drawing a new one.
---
# AI doesn't have a Moore's Law
URL: https://www.abhinav.co/ai-curves
Date: 2026-04-21T00:00:00+00:00
## It has something harder to name, and harder to ignore.
In January 2023, two months after ChatGPT launched, I started building [annexr](https://annexr.com). I thought I was late. Three years later, I realize I was early.
That mismatch - feeling late while being early - is the signature experience of building in AI right now. It has nothing to do with individual foresight. It has everything to do with how progress in this field compounds.
---
## One curve vs. many
Moore's Law was one curve: transistor density doubling on a predictable clock. Clean, measurable, predictive. And even that wasn't a natural law. At Intel, it was a goal the company worked hard to keep. When physics pushed back, they adapted.
AI progress isn't like that. There is no single company shepherding a single metric. It is a bundle of partially correlated curves: compute, algorithms, inference cost, hardware efficiency, and how long AI systems can work without a human in the loop.
What makes this unusual is that two different kinds of improvement run at once.
- [Moore's Law](https://en.wikipedia.org/wiki/Moore%27s_law) runs on the calendar. Time passes, chips improve.
- [Wright's Law](https://en.wikipedia.org/wiki/Experience_curve_effects) runs on cumulative work done. The more you make something, the cheaper it gets.
In AI, both are active simultaneously. That coupling is what makes progress feel relentless. The decoupling is what produces the walls.
---
## The curves, briefly
Four numbers worth knowing:
- **Training compute** has grown roughly 4.5x per year since 2010
- **Algorithmic efficiency** improves separately: the same capability now takes about 3x less compute each year
- **Inference cost** has fallen by orders of magnitude, anywhere from 9x to 900x per year depending on the task
- **Agent task horizon** - how long an AI can work before needing help - has been doubling roughly every four months
These aren't independent. Falling inference cost enables more compute at inference time, which improves reasoning, which pushes the task-horizon curve further, until it hits a wall.
---
## Where the curves break
**The logarithmic trap.** Benchmark performance scales roughly with the log of compute. Each doubling of performance costs far more than a doubling of the training budget. The current bet is test-time compute, shifting spend from training to reasoning during use. Whether the economics hold at scale is still open.
**The data wall.** High-quality human text is largely exhausted at frontier training scales. Synthetic data and model self-play have kept the curve alive in narrow domains like math and code. Whether they generalize is the open question.
**The reliability gap.** Task horizon measures length, not robustness. An agent that can work for a hundred hours but has a 1% chance of failure each hour is unusable for anything high-stakes. Reliability data lags capability data badly, which is itself a signal about what the industry has optimized for.
**The power grid.** Moore's Law was about density, doing more in the same space. AI scaling is about absolute magnitude. Bigger clusters need more gigawatts. Power grids follow civil engineering timelines, not silicon ones.
**The institutional curve, which is essentially flat.** Compliance, procurement, security review, change management: none of these scale exponentially. The AI curves are steep. The institutional curve is close to flat.
---
## What this means practically
The line of what is worth building keeps moving. Something too expensive or too unreliable last quarter can make sense this quarter. Something that barely works today can be boring infrastructure a year from now.
But the problems blocking real adoption have shifted. They are no longer mostly about capability. They are about reliability, power capacity, data quality, and how long it takes large organizations to trust new systems.
Most of the interesting work for the rest of this decade sits in closing the gap between a steep capability curve and a nearly flat institutional one. Not pushing the frontier further. Getting organizations to the threshold.
That is a harder problem than making the models smarter. It is also a more tractable one.
---
*If you want the backstory on how these three threads came together, I wrote about that separately: [The AI moment was seventy years in the making](/ai-three-lines).*
---
## Sources and further reading
- [Moore's Law](https://en.wikipedia.org/wiki/Moore%27s_law)
- [Wright's Law / Experience curve effects](https://en.wikipedia.org/wiki/Experience_curve_effects)
- [Epoch AI: Trends in frontier AI training compute and algorithmic efficiency](https://epoch.ai/trends)
- [Epoch AI: LLM inference price trends](https://epoch.ai/data-insights/llm-inference-price-trends)
- [METR: Measuring AI ability to complete long tasks (Jan 2026 update)](https://metr.org/blog/2026-1-29-time-horizon-1-1/)
- [Stanford HAI: AI Index Report](https://hai.stanford.edu/ai-index/2025-ai-index-report)
---
# The AI moment was seventy years in the making
URL: https://www.abhinav.co/ai-three-lines
Date: 2026-04-21T00:00:00+00:00
_Three independent lines of work. Each took decades. None waited for the others._
---
In 1947, Bell Labs invented the transistor. A year later, Claude Shannon, working in the same building, published a paper on the mathematics of communication. Neither discovery knew what it was starting.
What we call "the AI moment" is not one thing. It is the convergence of three threads, each of which matured on its own schedule, developed independently of the others.
---
## The first thread: a language for information itself
In 1948, [Claude Shannon](https://en.wikipedia.org/wiki/Claude_Shannon) published [_A Mathematical Theory of Communication_](https://en.wikipedia.org/wiki/A_Mathematical_Theory_of_Communication). He was trying to solve a practical problem: how do you transmit a signal reliably over a noisy channel?
What he produced was something much larger. A mathematical language for information itself. Entropy. Compression. Channel capacity. The idea that meaning could be separated from medium, quantified, and reasoned about formally.
It laid the mathematical foundation that machine learning, deep learning, and modern AI are built on. Every token prediction in a modern language model is a descendant of that paper. Shannon did not know he was laying the foundation for AI. He was solving a telephone problem.
---
## The second thread: hardware that could actually run the math
The [transistor](https://en.wikipedia.org/wiki/Transistor) was invented in 1947. Seven decades of shrinking, specializing, and parallelizing followed.
The moment hardware met modern AI visibly was 2012. A team at the University of Toronto trained a neural network called [AlexNet](https://en.wikipedia.org/wiki/AlexNet) on GPUs and won [ImageNet](https://en.wikipedia.org/wiki/ImageNet) by a margin that made everyone in the field stop and recalculate. GPUs were designed for graphics. They turned out to be the right shape for deep learning: massively parallel, fast at matrix operations, cheap enough to experiment with.
Google followed with custom silicon. TPUs arrived in 2016, designed specifically for neural network workloads. The physical substrate that made scale possible was now being purpose-built for it.
---
## The third thread: an architecture that changed everything
In June 2017, a team at Google published [_Attention Is All You Need_](https://arxiv.org/abs/1706.03762). The paper proposed the [Transformer](): a new architecture that dropped recurrence entirely and used attention mechanisms to process sequences in parallel.
Google understood it well enough to ship BERT in 2018 and T5 in 2019. What it did not do was productize at the pace the architecture deserved. The constraint was probably search revenue. If your core business is people finding answers on web pages, a model that answers questions directly is a threat you have to manage carefully.
OpenAI had no such constraint. GPT-2 in 2019. GPT-3 in 2020. The technical trajectory was visible to anyone watching. The three threads had already crossed.
---
## What actually happened in 2022
By the time ChatGPT launched in November 2022, nothing fundamental had changed in the underlying technology. The models were better, but the architecture, the hardware, the training approach: all of it had been in place for years.
What changed was the interface. A chat box that anyone could use. No API key. No prompting knowledge required. The intersection of seventy years of work was suddenly in front of everyone with an internet connection.
The rupture of 2022 was not a moment of invention. It was a moment of attention.
---
The three threads took different amounts of time. Shannon's 1948 paper needed sixty years of hardware before it could run at scale. The Transformer needed less than five years to go from research paper to the technology inside a product used by a hundred million people.
The gap between discovery and deployment has been shrinking the whole time. That, more than any single breakthrough, is what makes the current moment feel different from the ones before it.
---
_The follow-on question, where those curves are headed and where they break, is what I wrote about in [AI doesn't have a Moore's Law](/ai-curves)._
---
# Terminal is having a second life
URL: https://www.abhinav.co/terminal-is-having-a-second-life
Date: 2026-04-22T00:00:00+00:00
In 2001 I started with telnet.
I was a student at [BITS Pilani](https://www.bits-pilani.ac.in/) and [telnet](https://en.wikipedia.org/wiki/Telnet) was simply how you got to the internet. I used [Pine](https://en.wikipedia.org/wiki/Pine_(email_client)) to send email. [Lynx](https://en.wikipedia.org/wiki/Lynx_(web_browser)) to browse. The world came to me as text on a black screen and I thought nothing of it. It was just how computers worked.
Then GUIs got faster, browsers got richer, and the terminal slowly became the thing you minimised and forgot about. Developers kept using it. Everyone else moved on.
I kept using it too. At Yahoo in 2005, the terminal was where the real work happened. I was working on a big data processing pipeline and my QA system was a pipe. Feed the output through `grep`, filter it with `cut`, join datasets with `join`, scan compressed logs with `zcat` and `zgrep`. Each tool did one thing. The intelligence lived in how you chained them. And if something went wrong, the tool that failed said so. The pipeline stopped. You knew exactly where to look.
It felt powerful then. I didn't fully understand why.
---
I've spent the last two months building [vrk](https://vrk.sh) -- Unix-style tools for LLM pipelines -- and the Yahoo pipeline keeps coming back to me.
Not as nostalgia. As explanation.
AI agents need to do things: fetch a URL, check it fits within a model's token limit, redact secrets, call the model, validate the output. The problem is what happens when something goes wrong. A model doesn't crash on bad input. It guesses. It fills in what it didn't see with text that sounds right. You find out three steps later, or you don't find out at all.
Agents, like the shell, are probabilistic at the edges but need determinism at the joints. The pipes are the joints.
That's the insight I kept arriving at while building vrk. The contract that made `grep` useful -- stdin in, stdout out, exit loudly on failure -- turns out to be exactly the contract an agent pipeline needs.
---
I started using the terminal because it was all there was. I keep using it because nothing that came after improved on the pipe.
---
# Introducing Soniq
URL: https://www.abhinav.co/soniq
Date: 2026-05-03T00:00:00+00:00
## Soniq - the job queue for people who don't want another job queue
I've been rebuilding the same job scheduler since 2011.
The first version used MongoDB. The core trick was `find_and_modify` -- MongoDB's atomic operation that lets you fetch a document and update it in a single step. Claim a job before anyone else does, or don't claim it at all. No double processing. I ran a [hosted multi-tenant version](https://github.com/abhinavs/scheduler_service) for two or three years. People used it. It mostly worked.
Then I moved on. But the problem stayed with me.
---
Over the years I've used most of the serious job queue libraries. Resque and Sidekiq in Ruby. RQ in Python. Each one solved the core problem well enough. Each one also required something extra: Redis, a specific runtime, or an entirely different programming model. The closest thing to what I wanted was Oban in Elixir -- PostgreSQL-backed, no broker, no Redis. But I was building in Python.
I kept thinking about the infra cost. Not the money, but the maintenance. Every component you add to a production system is something that can fail, something you have to monitor, something you have to explain to whoever reads your deploy config next. Redis is not expensive to run. But Redis is one more thing to run.
I believe in [boring infrastructure](https://mcfunley.com/choose-boring-technology). The best infra component is usually the one you don't add. Most Python applications already run PostgreSQL. Your jobs can too. It's already there. It's already backed up. You already understand it.
---
Last year I built Fastjob. PostgreSQL as the datastore, transactional enqueue, dashboard, webhooks, scheduler. Feature-rich. I'm also willing to admit it became complicated. I added things before the core was solid, and eventually the project became what I was trying to avoid: one more thing to manage.
In January this year I started again, on weekends. I call it Soniq.
---
Soniq is a batteries-included async job queue for Python. The only infrastructure dependency is PostgreSQL.
No Redis cluster. No separate broker. No operational split brain between your app state and your queue state.
If your application already depends on PostgreSQL, your queue can too.
What that gives you that most queues don't:
- Transactional enqueue. A job is either committed or it isn't. A user signs up, the database transaction commits, the welcome email job commits in the same transaction - there is no gap where one succeeds and the other disappears.
- Built-in scheduler and recurring jobs
- Built-in dashboard, no paid tier
- Prometheus metrics out of the box
Most applications don't need a dedicated distributed queue cluster just to send emails and process background tasks. Soniq is built for that majority - teams that need reliability and operational simplicity more than extreme throughput.
If you're already running PostgreSQL and don't want another broker, [Soniq is ready](https://github.com/abhinavs/soniq) - MIT licensed, batteries included.
---
# Introducing sqlalchemy-annotate
URL: https://www.abhinav.co/sqlalchemy-annotate
Date: 2026-05-19T00:00:00+00:00
I have released `sqlalchemy-annotate`, a small command-line tool that keeps a schema summary at the top of every SQLAlchemy model file.
When you read a SQLAlchemy model, the Python tells you which attributes exist but not what the database does with them. Whether a column is nullable, how long a string can be, which columns are indexed, what the foreign keys point at - none of that is visible in the model. You have to open the migration or connect to the database to find out. Rails has addressed this for years with `annotate_models`. This tool brings the same idea to modern SQLAlchemy 2.x and Alembic projects.
It maintains a block like this, kept in sync with your actual metadata:
```
# == Schema Information
#
# Table name: users
#
# id : integer, primary key
# email : varchar, not null
# created_at : timestamp
#
# Indexes
# ix_users_email (email) UNIQUE
#
# == End Schema Information
```
There are three commands. `sqlalchemy-annotate generate` writes or updates the block, typically run after a migration. `sqlalchemy-annotate check` exits non-zero when a model has drifted from its comment, which makes it suitable as a CI gate or pre-commit hook. `sqlalchemy-annotate remove` strips every block.
Two design decisions are worth stating directly.
First, it never connects to a database. The schema is read from `Base.metadata`. If you pass a connection URL, only its dialect is used, so types compile correctly offline, and the URL is then discarded. Annotating a file does not require database credentials.
Second, it does not rewrite files with regular expressions. All edits go through a single libcst transformer, so imports, comments, blank lines and formatting outside the marked block are preserved exactly. Running `generate` twice produces no further change, which is what makes `check` reliable.
One trade-off should be clear before you adopt it. The tool imports your model package, in the same way pytest and Alembic do. If importing your models triggers side effects, those will run. For most projects this is not an issue, but it is worth knowing.
Installation is from PyPI:
```
pip install sqlalchemy-annotate
```
The source, full documentation and configuration options are at [github.com/abhinavs/sqlalchemy-annotate](https://github.com/abhinavs/sqlalchemy-annotate). The tool is intentionally small. The schema already exists in your metadata; this simply puts it where the person reading the model can see it.